
皆様、こんにちは。h.serizawaです。
Jupyter Notebookによるデータ分析環境を構築しました。この記事では、環境構築からデータ分析の実践まで、実際の手順とともに紹介します。
※本記事はOracle Cloud Infrastructure Advent Calendar 2025シリーズ4 Day25 の記事です!
目次
- 1 なぜデータ分析環境が必要なのか?
- 2 OCI + Jupyter Notebook
- 3 Jupyter Notebookとは?
- 4 Python仮想環境とは?
- 5 環境構築の流れ
- 5.1 ステップ1:Compute Instanceの作成
- 5.2 ステップ2:SSH接続の準備
- 5.3 ステップ3:セキュリティ設定
- 5.4 ステップ4:サーバーへのSSH接続
- 5.5 ステップ5:Python環境のセットアップ
- 5.6 ステップ6:仮想環境の作成
- 5.7 ステップ7:データ分析ライブラリのインストール
- 5.8 ステップ8:Jupyter Notebookの設定
- 5.9 ステップ9:Jupyter Notebookの起動
- 5.10 ステップ10:ブラウザからアクセス
- 5.11 ステップ11:最初のNotebookを作成
- 5.12 ステップ12:基礎編 OCIコストデータで分析
- 5.13 ステップ13:実践編 Object Storageからデータ読み込み
- 6 まとめ
なぜデータ分析環境が必要なのか?
データ分析を始めようとすると、こんな悩みに直面したことはありませんか?
「Excelでの集計に時間がかかりすぎる...」 「自分のPCではメモリが足りなくて重いデータが開けない...」 「会社でしか作業できない環境に縛られている...」
Excelだけでは限界がある
Excelは便利ですが、データ分析において以下のような課題があります。
❌ 大量データの処理が遅い(数万行を超えると重くなる)
❌ 複雑な統計処理が難しい(手作業でグラフを作るのに時間がかかる)
❌ 分析の再現性が低い(手順を記録できない)
❌ 機械学習などの高度な分析ができない
解決方法:クラウド上のデータ分析環境
これまでは、以下のような選択肢がありました。
選択肢1: 自分のPCにPythonをインストール
- PCのスペックに依存する
- 環境構築で挫折しやすい
- 会社のPCでは管理者権限がなくてインストールできない
選択肢2: 有料のクラウドサービス
- Google Colab Pro: 月額1,000円〜
- AWS SageMaker: 使った分だけ課金
- Azure Notebooks: 月額数千円〜
この方法のデメリット
💰 コストがかかる - 毎月の支払いが発生
🔧 設定が複雑 - サービスごとに学習コストが高い
📊 データ保存の制限 - 無料枠には厳しい制限がある
お客様からの要望と制約
データ分析環境を提案すると、以下のような要望や制約に直面します。
🏢 コスト制約 「予算が限られているので、できるだけ無料で使いたい」
💼 シンプルな運用 「複雑な設定は避けたい。すぐに使い始めたい」
📊 アクセス性 「どこからでもアクセスできる環境がほしい」
しかし、無料で使えるクラウド環境には制限が多い...
OCI + Jupyter Notebook
そこで、今回のJupyter Notebook環境の構築方法を紹介します。
仕組み
- OCI Compute Instance: サーバーを提供
- Python仮想環境: プロジェクト専用の作業スペース
- Jupyter Notebook: ブラウザで動く分析環境
- Object Storage: データを保存
この方式のメリット
| 項目 | 従来の方法 | OCI |
|---|---|---|
| コスト | 月額1,000円〜 | 完全無料 |
| 環境構築 | PCごとに設定が必要 | 一度構築すればOK |
| アクセス | 特定のPCからのみ | どこからでもブラウザでアクセス |
| データ保存 | ローカルストレージ | Object Storage(20GB無料) |
| スペック | PCに依存 | 1CPU、1GBメモリ(拡張可能) |
| 保守 | 自分でメンテナンス | OCI側で管理 |
実現できること
💾 データ分析: Pandas、NumPyで高速処理
📊 可視化: Matplotlib、Seabornで綺麗なグラフ作成
🤖 機械学習: Scikit-learnで予測モデル構築
☁️ クラウド連携: Object Storageからデータ読み込み
🌐 リモートアクセス: 自宅、カフェ、どこからでもアクセス
誰にとってメリットがあるか
ビジネスユーザーにとって:
📈 Excelの10倍速でデータ処理(業務効率化)
🎯 どこからでもアクセス可能(リモートワーク対応)
🔒 データをクラウドに安全に保存(バックアップ不要)
エンジニアにとって:
🚀 案件で即座に提案できる(「無料で始められます」と言える)
🔧 スケーラブル(必要に応じてスペック拡張可能)
💼 標準化されたワークフロー(毎回同じ手順)
Jupyter Notebookとは?
ブラウザで動くプログラミング環境
Jupyter Notebook(ジュピター・ノートブック)は、ブラウザで動くプログラミング環境です。
従来のプログラミングとの違い
| 従来のプログラミング | Jupyter Notebook |
|---|---|
| エディタでコード作成 → 保存 → 実行 → 結果確認 | ブラウザで書く → すぐ実行 → その場で結果表示 |
| ターミナル操作が必要 | ブラウザだけで完結 |
| コードと結果が別 | コードと結果が一緒に保存 |
データ分析に最適な理由
✓ 対話的: 1行ずつ実行して結果を確認できる
✓ 視覚的: グラフや表が綺麗に表示される
✓ 文書化: コードと説明を一緒に書ける
✓ 共有が簡単: .ipynbファイル1つで完結
世界中のデータサイエンティストが使っている標準ツールです!
Python仮想環境とは?
プロジェクト専用の作業スペース
仮想環境を部屋に例えると理解しやすいです。
仮想環境なし:
部屋全体に物を置く → どこに何があるか分からない → 新しい物を入れたら前の物が動かなくなった仮想環境あり:
部屋の中に「専用の箱」を作る → Jupyter用の箱、他のプロジェクト用の箱 → それぞれ独立
なぜ仮想環境を使うのか?
✓ 安全: 間違って削除しても他に影響しない
✓ 管理が簡単: バージョン違いのライブラリを共存できる
✓ 削除が簡単: 箱ごと削除するだけ
今回作る仮想環境
- 名前:
jupyter-env - 場所:
/home/opc/jupyter-env - 中身: Jupyter Notebook + データ分析ライブラリ
環境構築の流れ
ステップ1:Compute Instanceの作成
OCIコンソールでサーバーを作成します。
- 左上のハンバーガーメニュー(≡)をクリック
- 「コンピュート」 → 「インスタンス」 を選択
- 「インスタンスの作成」 ボタンをクリック
1-1. 基本情報の入力
1-2. イメージとシェイプの選択
イメージ:
- Oracle Linux 10 を選択
シェイプ:
- VM.Standard.E2.1.Micro を選択(Always Free対象)
- CPU: 1 OCPU
- メモリ: 1 GB
1-3. ネットワーキングの設定
設定値:
- 仮想クラウド・ネットワーク: 新規作成
- サブネット: 新規パブリック・サブネット
- ✅ パブリックIPv4アドレスの割当て: チェック必須
⚠️ 重要: パブリックIPがないとブラウザからアクセスできません!
1-4. SSHキーの追加
おすすめ方法: 自動生成
- 「SSHキー・ペアの生成」 を選択
- 「秘密キーの保存」 をクリック
- 「公開キーの保存」 をクリック
⚠️ 重要: 秘密キーは大切に保管してください。
1-5. ブートボリュームの設定
デフォルトのまま(50GB)でOK
1-6. インスタンスの作成
「作成」 ボタンをクリックします。
ステータスが 「実行中」 になるまで待ちます(約1〜2分)。
1-9. パブリックIPアドレスのメモ
インスタンス詳細画面で、パブリックIPアドレスをメモします。
例: 132.145.XXX.XXX
💡 このIPアドレスは後で使います。
ステップ2:SSH接続の準備
2-1. SSHキーファイルの権限設定
# ダウンロードフォルダに移動cd ~/Downloads # 権限を変更chmod 600 xxx.key

ステップ3:セキュリティ設定
Jupyter Notebookにアクセスできるよう、2つのファイアウォールを設定します。
💡 なぜ2つ必要?
- OCIセキュリティリスト(クラウド側)
- firewalld(サーバー側)
両方開放しないと外部からアクセスできません。
3-1. OCIセキュリティリストの設定
VCNの詳細画面へ移動
- ハンバーガーメニュー → 「ネットワーキング」 → 「仮想クラウド・ネットワーク」
- 作成した 仮想クラウド・ネットワーク をクリック
セキュリティリストの編集
- 左側のリソースメニューで 「セキュリティ・リスト」 をクリック
- 「Default Security List」 をクリック
- 「イングレス・ルールの追加」 をクリック
ポート8888のルールを追加
設定値:
- ソース・タイプ: CIDR
- ソースCIDR:
0.0.0.0/0 - IPプロトコル: TCP
- 宛先ポート範囲:
8888 - 説明:
Jupyter Notebook access
[画像17: Jupyter Notebook access用のセキュリティリスト_イングレスルール追加_data-analysis-server.jpg]
💡 ポート8888とは?: Jupyter Notebookのデフォルトポートです。
ステップ4:サーバーへのSSH接続
4-1. SSH接続
cd ~/Downloads
ssh -i ssh-key-2025-01-25.key opc@132.145.XXX.XXXこのプロンプトが表示されれば成功です!
ステップ5:Python環境のセットアップ
5-1. システムのアップデート
# システムパッケージを最新に更新sudo dnf update -y
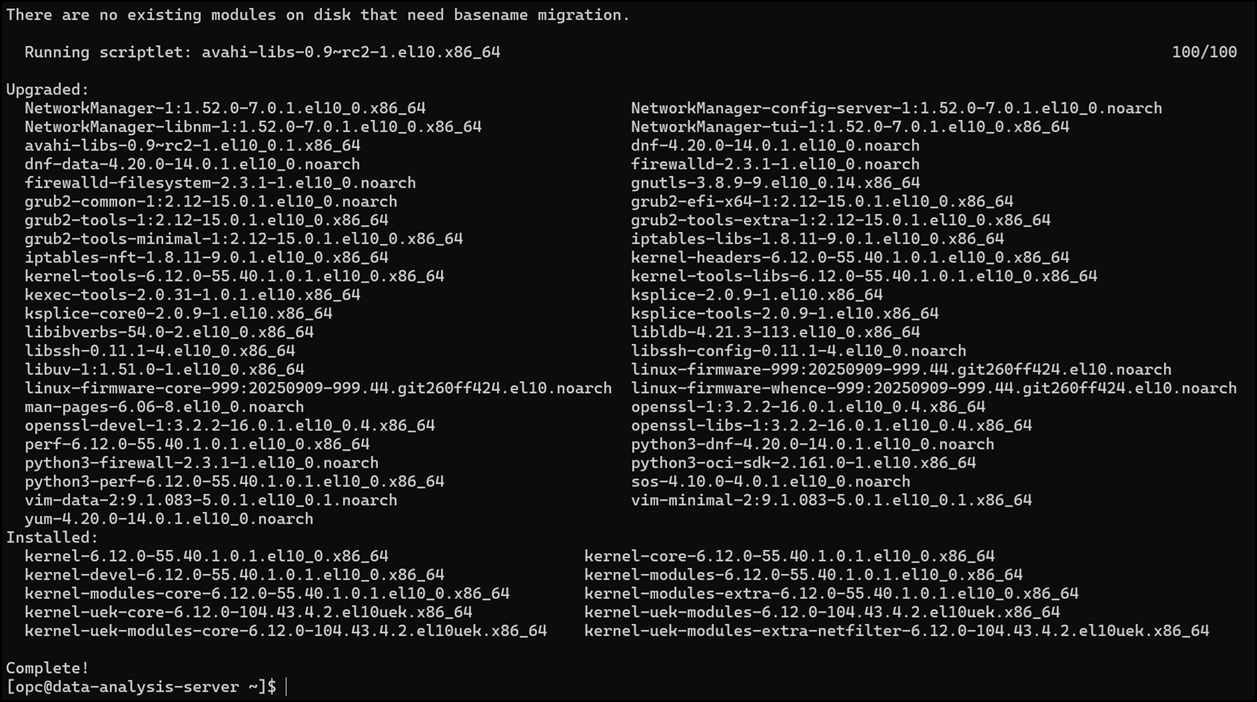
💡 説明: サーバーのソフトウェアを最新にします。数分かかります。
5-2. Python 3とpipのインストール
# Python 3とpipをインストールsudo dnf install -y python3 python3-pip python3-devel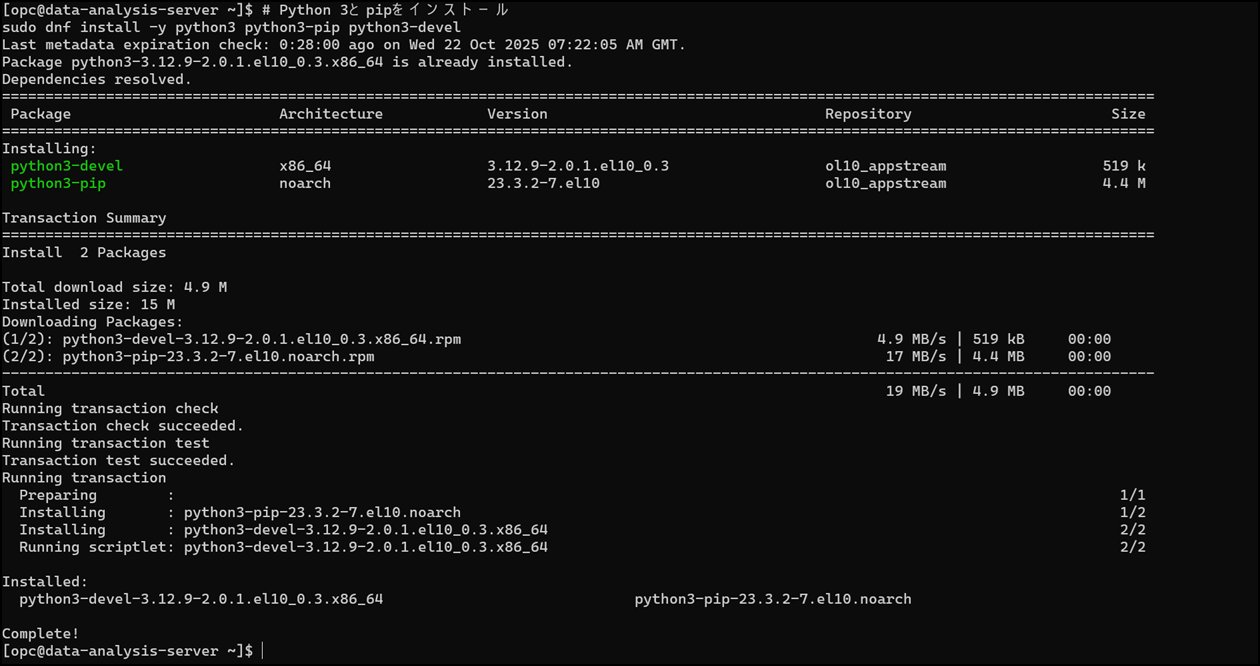
5-3. Pythonバージョンの確認
# Pythonのバージョン確認python3 --version
Python 3.12.9 と表示されればOKです。
ステップ6:仮想環境の作成
6-1. 仮想環境の作成
# 仮想環境を作成python3 -m venv ~/jupyter-env💡 説明:
python3 -m venv= 仮想環境を作るコマンド~/jupyter-env= 作成場所と名前
6-2. 仮想環境の有効化
# 仮想環境を有効化source ~/jupyter-env/bin/activate
```プロンプトが以下のように変わればOKです:
```
(jupyter-env) [opc@data-analysis-server ~]$
💡 重要: (jupyter-env) が表示されている間は仮想環境内で作業しています。
ステップ7:データ分析ライブラリのインストール
7-1. pipのアップグレード
# pipを最新版にアップグレードpip install --upgrade pip7-2. Jupyter Notebookのインストール
# Jupyter Notebookをインストールpip install jupyter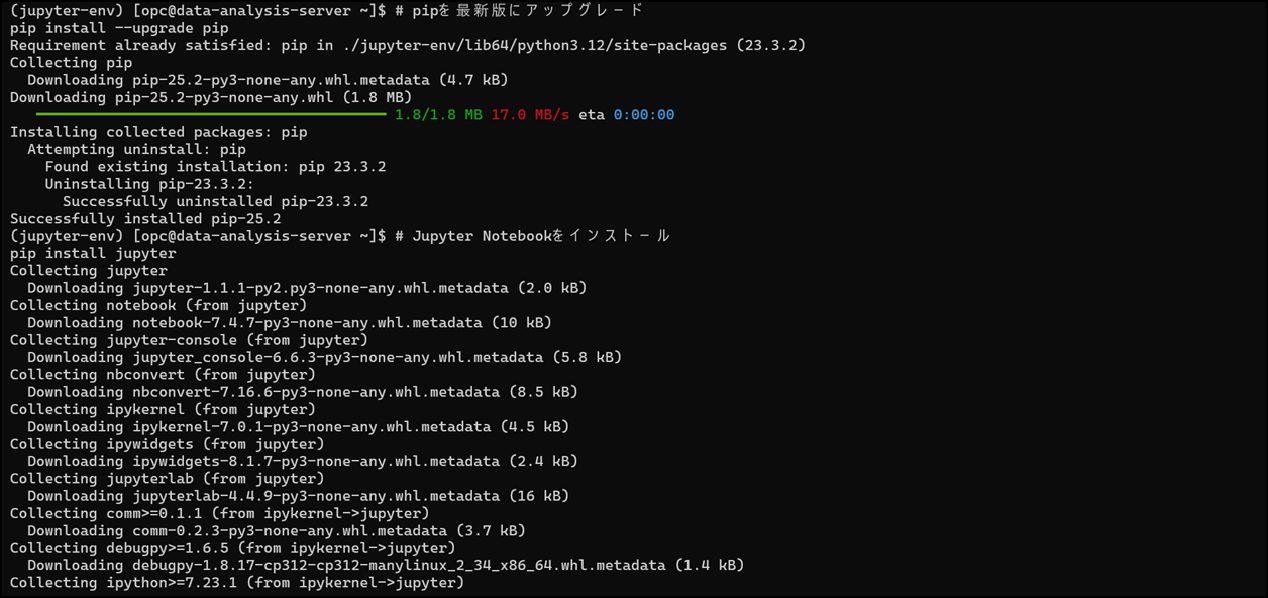
インストールには数分かかります。☕
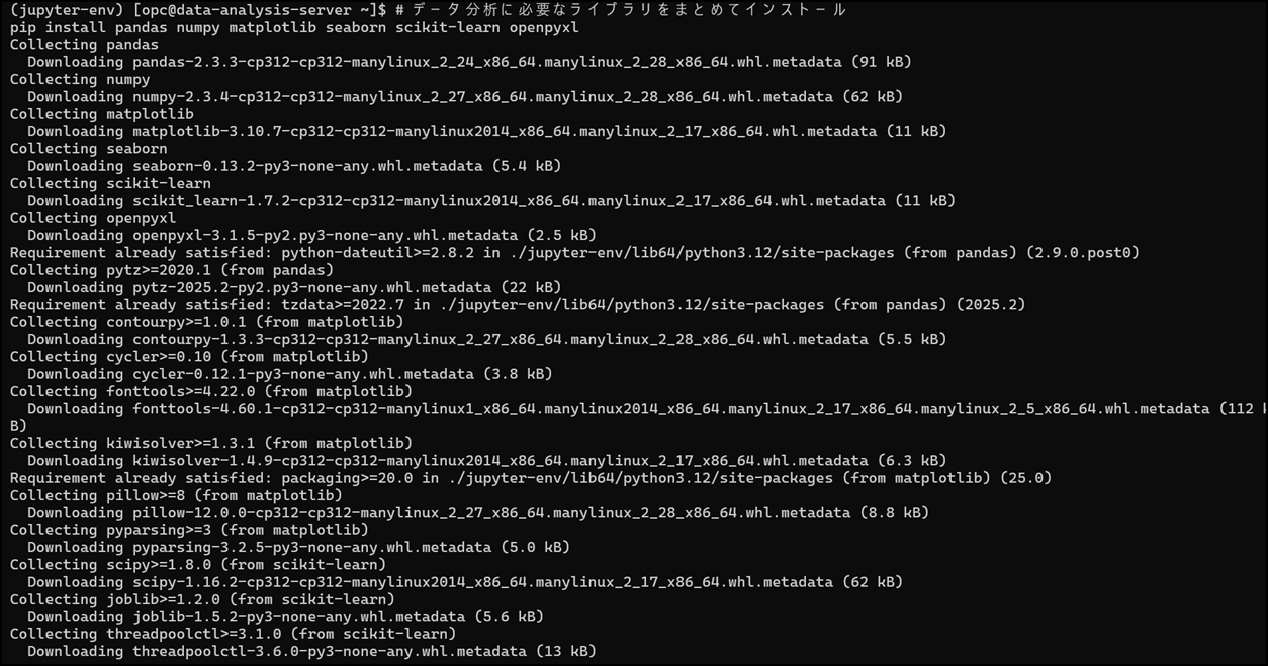
7-3. データ分析ライブラリのインストール
# データ分析ライブラリをまとめてインストールpip install pandas numpy matplotlib seaborn scikit-learn openpyxl💡 各ライブラリの説明:
| ライブラリ | 用途 |
|---|---|
| pandas | データ分析の基本(表データ処理) |
| numpy | 数値計算 |
| matplotlib | グラフ描画 |
| seaborn | 綺麗なグラフを簡単に作成 |
| scikit-learn | 機械学習 |
| openpyxl | Excelファイルの読み書き |
インストールには5〜10分かかります。
ステップ8:Jupyter Notebookの設定
8-1. 設定ファイルの生成
# 設定ファイルを生成jupyter notebook --generate-config8-2. パスワードの設定
# パスワードを設定jupyter notebook passwordパスワードを2回入力します。忘れないようにメモしてください。

8-3. 設定ファイルの編集
# viで設定ファイルを編集vi ~/.jupyter/jupyter_notebook_config.py
以下の3行を追加します:
c.NotebookApp.ip = '0.0.0.0' c.NotebookApp.open_browser = False c.NotebookApp.port = 8888
💡 各設定の意味:
ip = '0.0.0.0': 外部からアクセス可能にするopen_browser = False: サーバー上でブラウザを開かないport = 8888: ポート8888で起動
8-4. サーバー側ファイアウォールの設定
# ファイアウォールの状態確認sudo systemctl status firewalld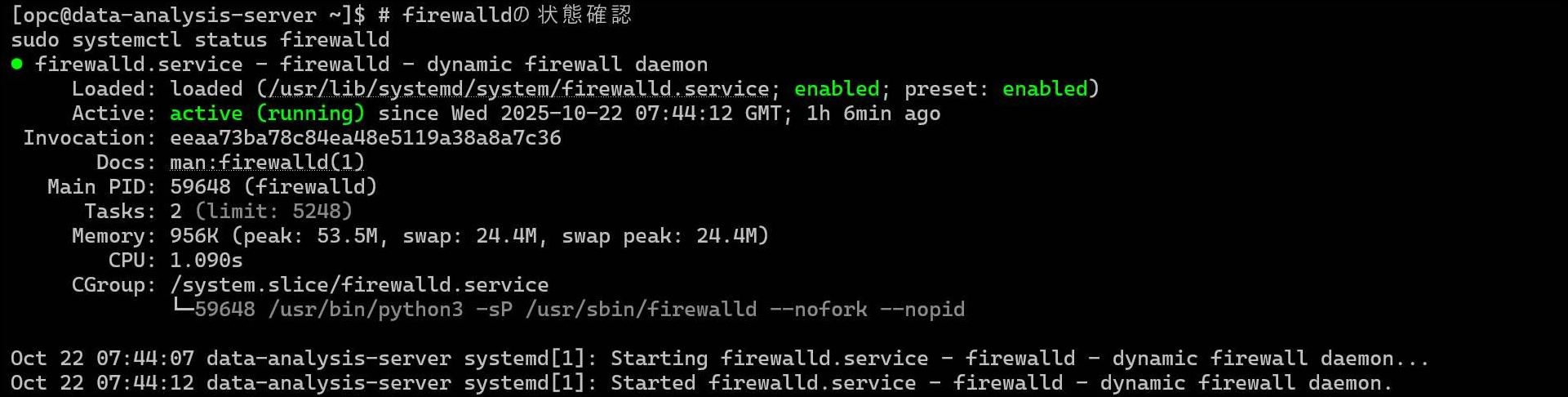
「active (running)」と表示された場合は、ファイアウォールが動いています。
💡 なぜ2つのファイアウォール設定が必要?: OCI側のベストプラクティスとして「VCNルール(クラウド側)+ firewalld(ホスト側)の多層防御」を推奨しています。両方でポート8888を開放する必要があります。
ステップ9:Jupyter Notebookの起動
9-1. 作業ディレクトリの作成
# Notebookを保存するディレクトリを作成mkdir ~/notebooks
cd ~/notebooks9-2. Jupyter Notebookの起動
# Jupyter Notebookを起動
jupyter notebook

以下のメッセージが表示されます。
[I 2025-10-22 08:12:28.130 ServerApp] Jupyter Server 2.17.0 is running at:
[I 2025-10-22 08:12:28.130 ServerApp] http://localhost:8888/tree

💡 注意: このターミナルウィンドウは閉じないでください。
ステップ10:ブラウザからアクセス
10-1.アドレスバーに以下を入力
http://132.145.XXX.XXX:8888
💡 注意: IPアドレスは自分のものに置き換えてください。
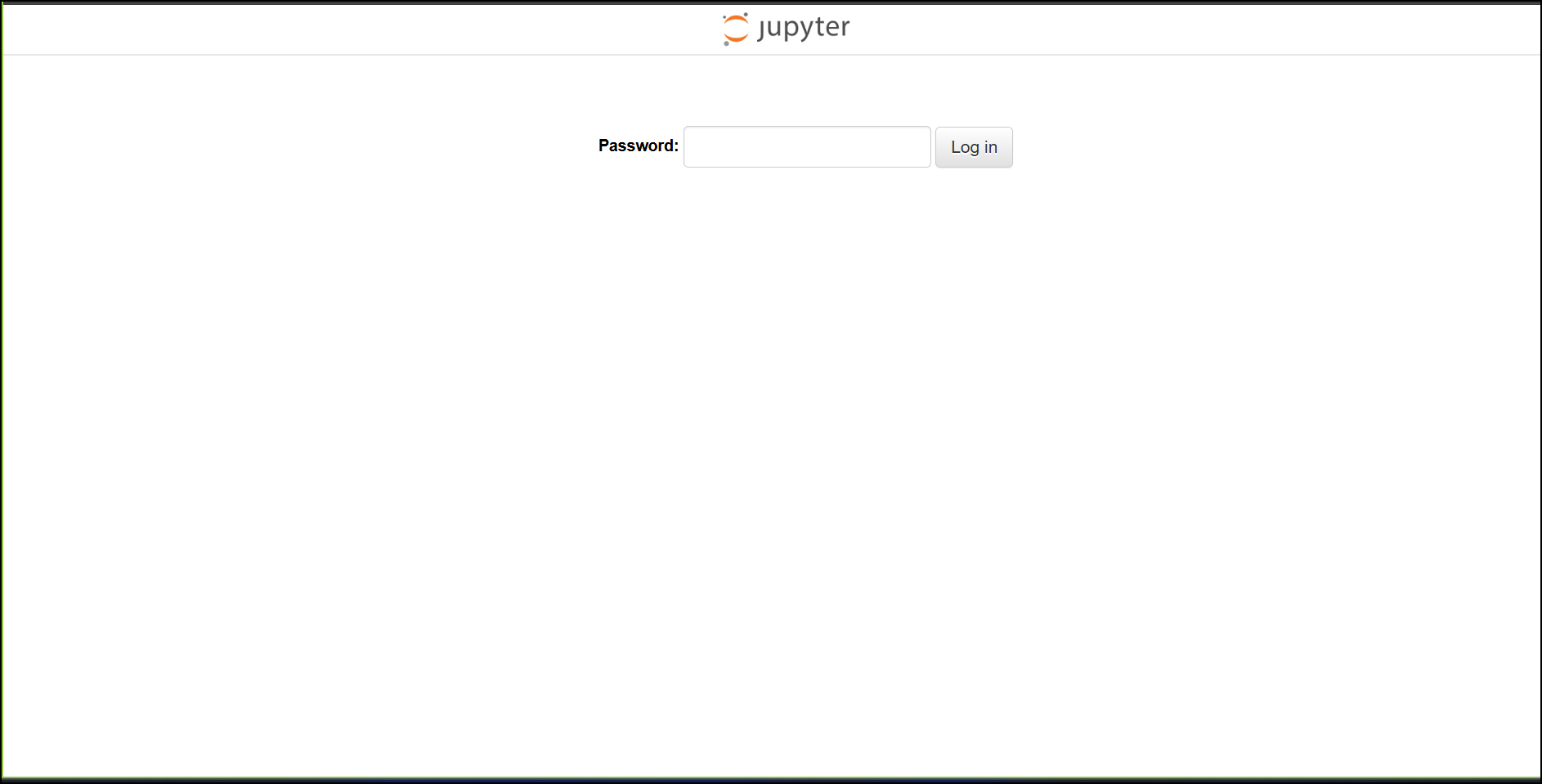
10-2. ログイン
パスワードを入力して 「Log in」 をクリックします。
ステップ11:最初のNotebookを作成
11-1. 新しいNotebookの作成
- 「New」 → 「Python 3」 をクリック
11-2. 最初のコードを実行
print("Hello, XXX!")Shift + Enter で実行します。
11-3. Notebookの保存
Ctrl + Sで保存します。
Notebookのタイトルをクリックして名前を変更できます。
- 例:
first_notebook
11-4. 基本操作
| 操作 | ショートカット |
|---|---|
| セルを下に追加 | B |
| セルを上に追加 | A |
| セルを削除 | DD(Dを2回) |
| Markdownに変更 | M |
| Codeに変更 | Y |
💡 ヒント: H キーでショートカット一覧が表示されます!
ステップ12:基礎編 OCIコストデータで分析
実際にOCIコストデータを分析してみましょう!
12-1. ライブラリのインポート
新しいセルに以下を入力して実行(Shift + Enter):
# データ分析ライブラリをインポート
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# グラフを綺麗に表示する設定%matplotlib inline
print("すべてのライブラリが正常にインポートされました!")
print("Pandas バージョン: {version}")
print("NumPy バージョン: {version}")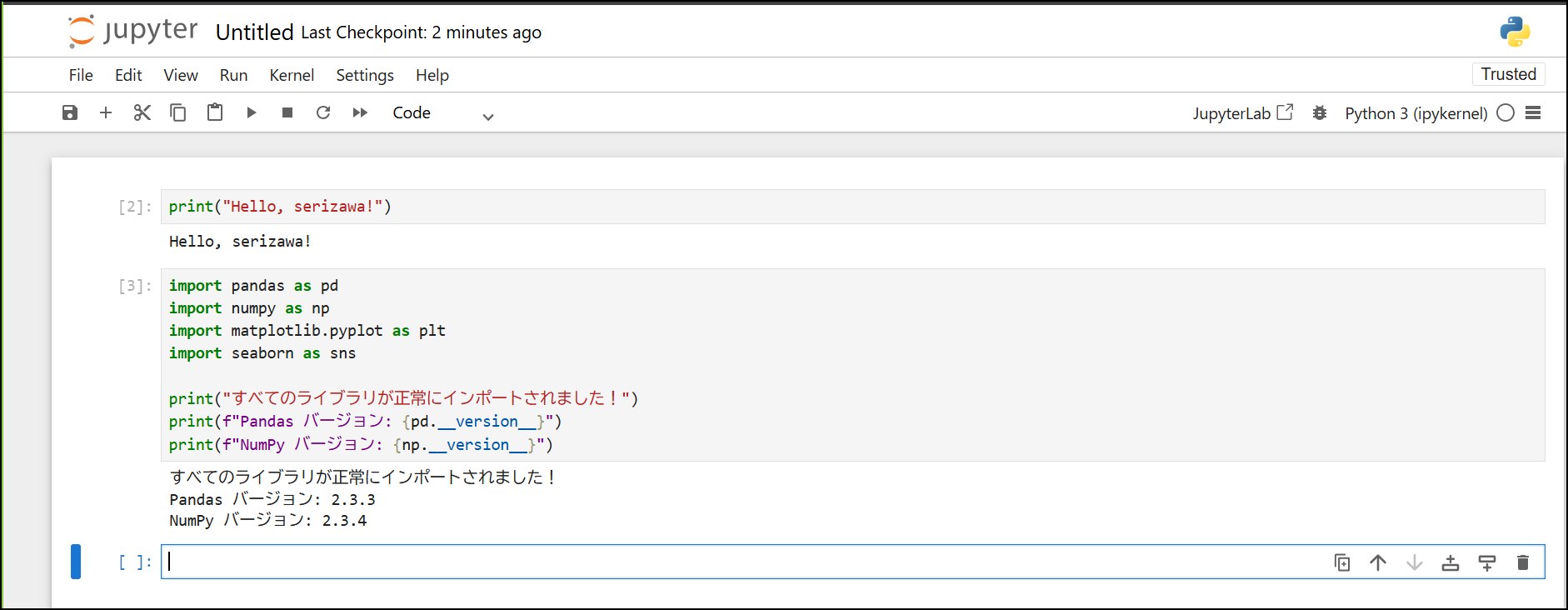
ステップ13:実践編 Object Storageからデータ読み込み
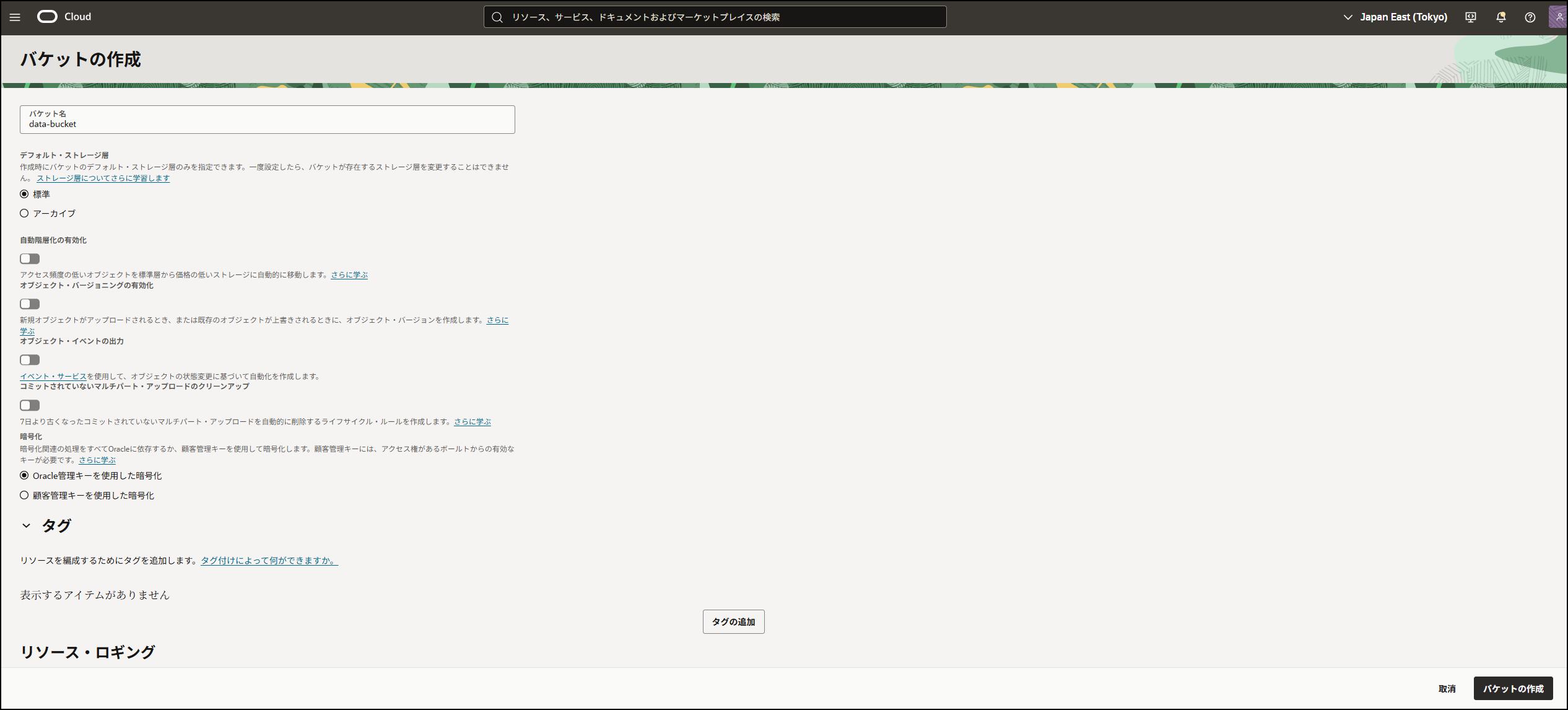
13-1. Object Storageの準備
バケットの作成:
- OCIコンソール → 「ストレージ」 → 「バケット」
- 「バケットの作成」 をクリック
- 「作成」 をクリック
13-2. サンプルCSVファイルの準備
サンプルCSV(sample_oci_costs.csv)を作成します
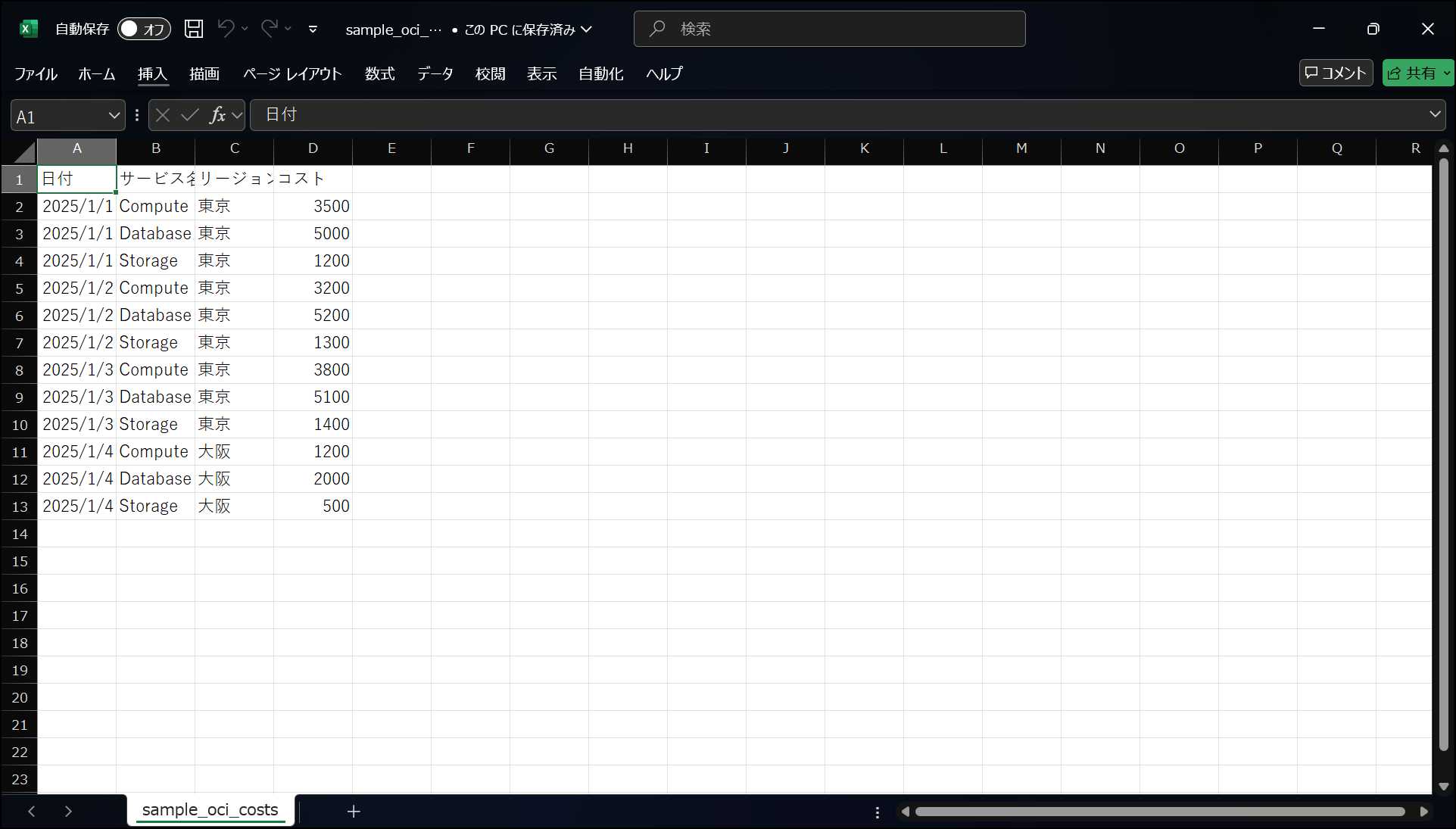
13-3. CSVファイルのアップロード
手順:
- バケット詳細画面で 「オブジェクトのアップロード」 をクリック
- アップロード完了を確認
13-4. 事前認証済リクエスト(PAR)の作成
手順:
- アップロードしたファイルの右側メニューをクリック
- 「事前認証済リクエストの作成」 を選択
- 設定値を入力:
- 名前
- アクセス・タイプ: 「オブジェクトの読取りと書込みを許可」 を選択
- 有効期限: 適切な日時を設定(例: 1ヶ月後)
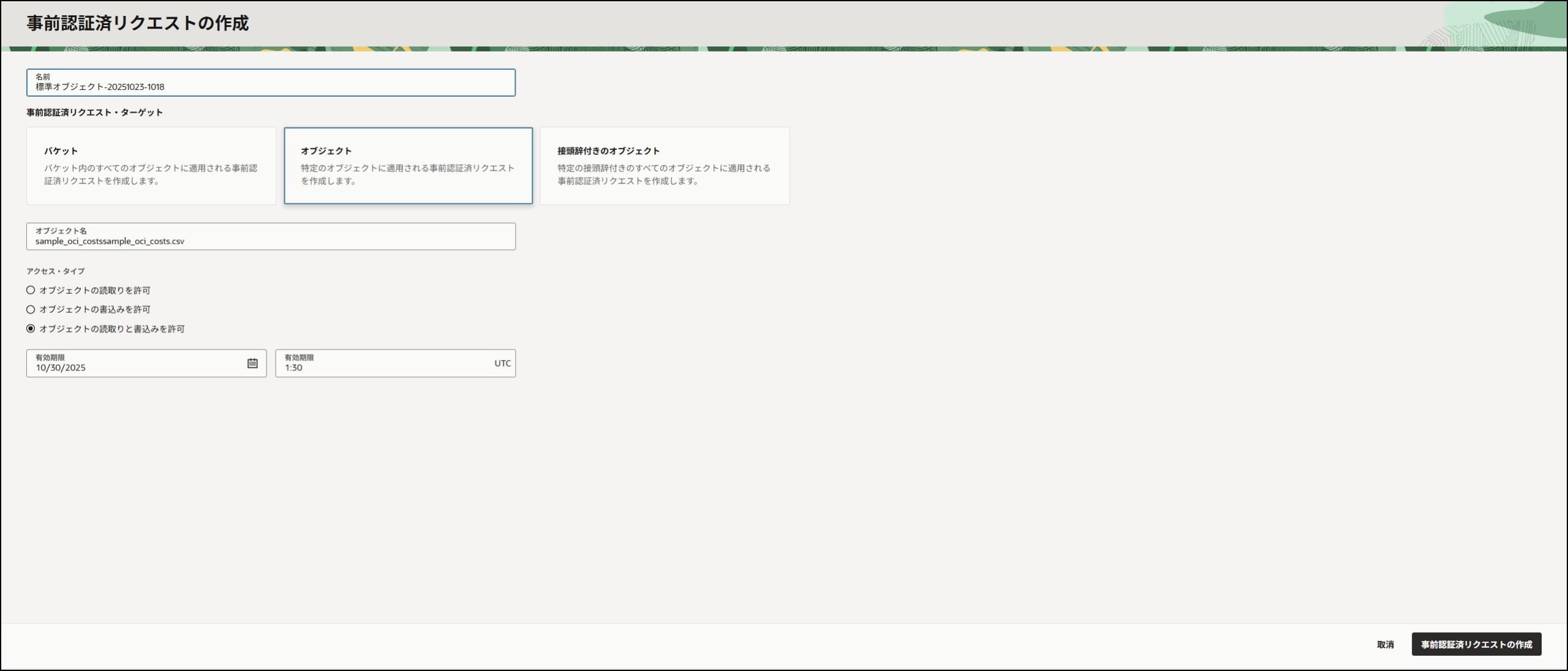
- 「事前認証済リクエストの作成」 をクリック
- URLをコピー
⚠️ 重要: このURLは一度しか表示されません!必ずコピーしてメモしておいてください。
13-5. Jupyter NotebookからObject Storageにアクセス
import pandas as pd
# 事前認証済リクエストのURLurl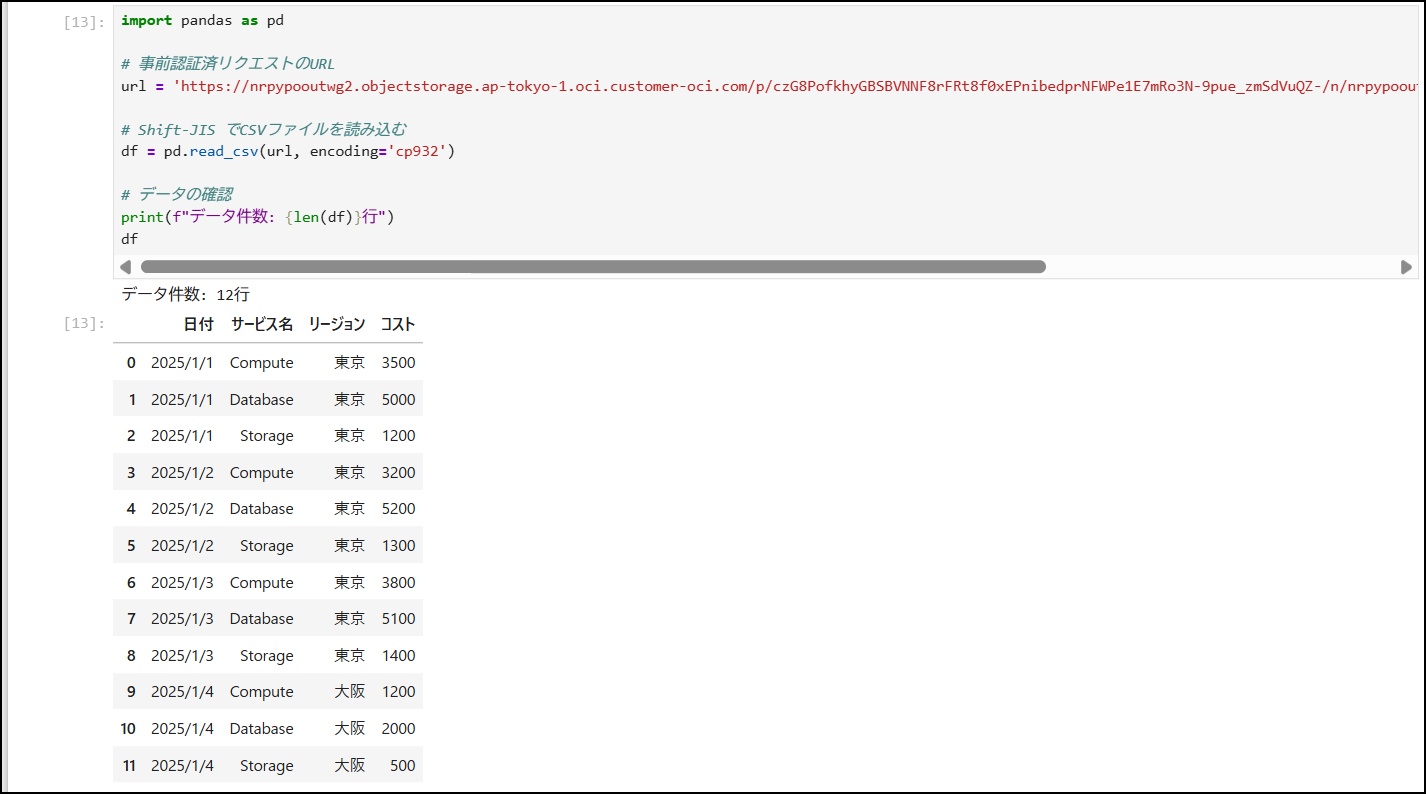
結果: Object Storageから直接データが読み込まれます!
13-6. データの基本情報を確認
# データの構造を確認
print("=== データ情報 ===")
df.info()
print("\n=== 基本統計量 ===")
df.describe()
print("\n=== 列名一覧 ===")
print(df.columns.tolist())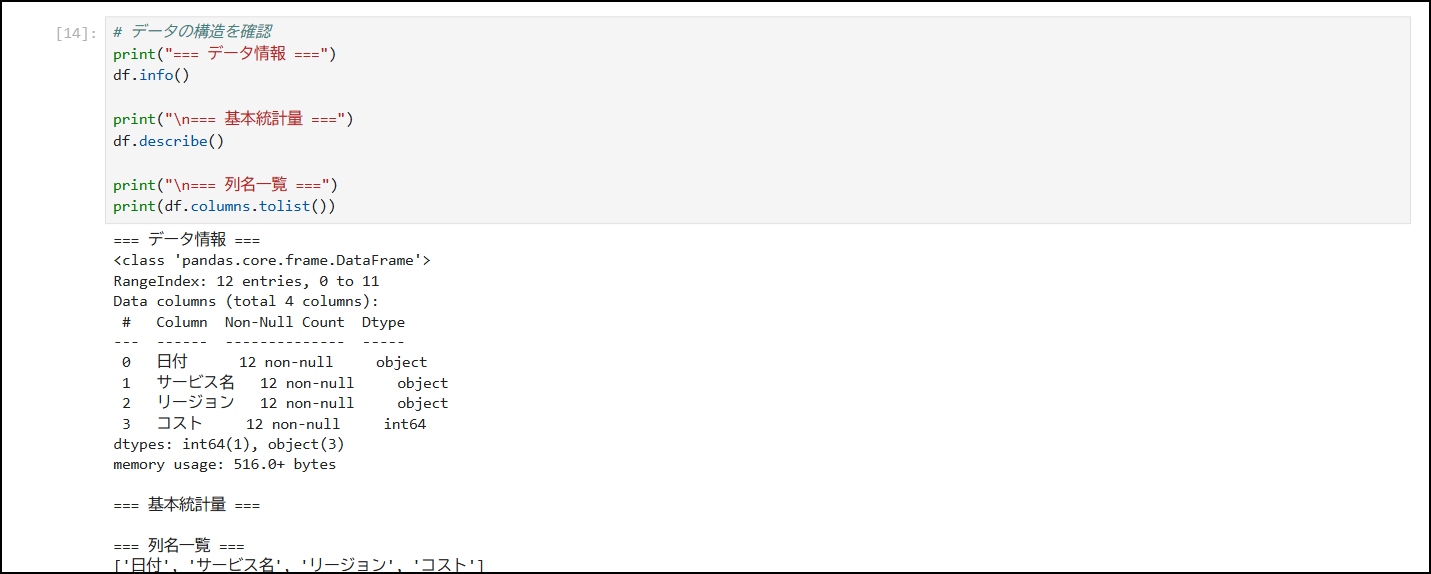
13-7. サービス別コストを集計
# サービス別の合計コストservice_total = df.groupby('サービス名')['コスト'].sum().sort_values(ascending=False)
print("=== サービス別合計コスト ===")
print(service_total)
13-8. リージョン別コストを集計
# リージョン別の合計コスト
region_total = df.groupby('リージョン')['コスト'].sum()
print("=== リージョン別合計コスト ===")
print(region_total)
13-9. サービス別コストを棒グラフで可視化
import matplotlib.pyplot as plt
# グラフ表示の設定
%matplotlib inline
# サービス別コストの棒グラフ
plt.figure(figsize=(10, 6))
service_total.plot(kind='bar', color=['#FF6B6B', '#4ECDC4', '#45B7D1'])
plt.title('Service Cost Summary (Total)', fontsize=14, fontweight='bold')
plt.xlabel('Service', fontsize=12)
plt.ylabel('Cost (JPY)', fontsize=12)
plt.xticks(rotation=45)
plt.grid(axis='y', alpha=0.3)
plt.tight_layout()
plt.show()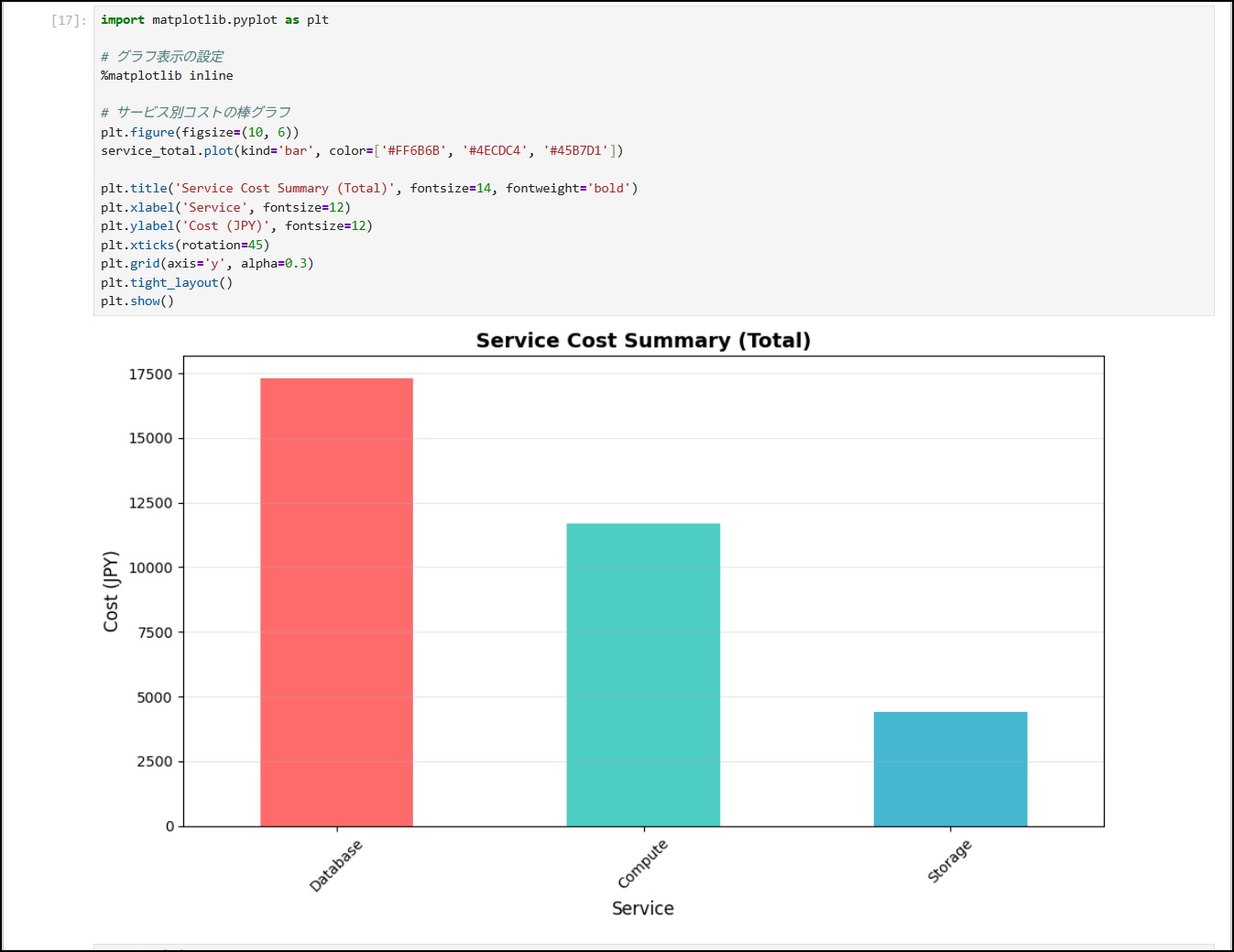
13-10. 日別コスト推移を折れ線グラフで可視化
# 日別の合計コスト
daily_cost = df.groupby('日付')['コスト'].sum()
plt.figure(figsize=(12, 6))
plt.plot(daily_cost.index, daily_cost.values, marker='o', linewidth=2, markersize=8)
plt.title('Daily Total Cost Trend', fontsize=14, fontweight='bold')
plt.xlabel('Date', fontsize=12)
plt.ylabel('Total Cost (JPY)', fontsize=12)
plt.xticks(rotation=45)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()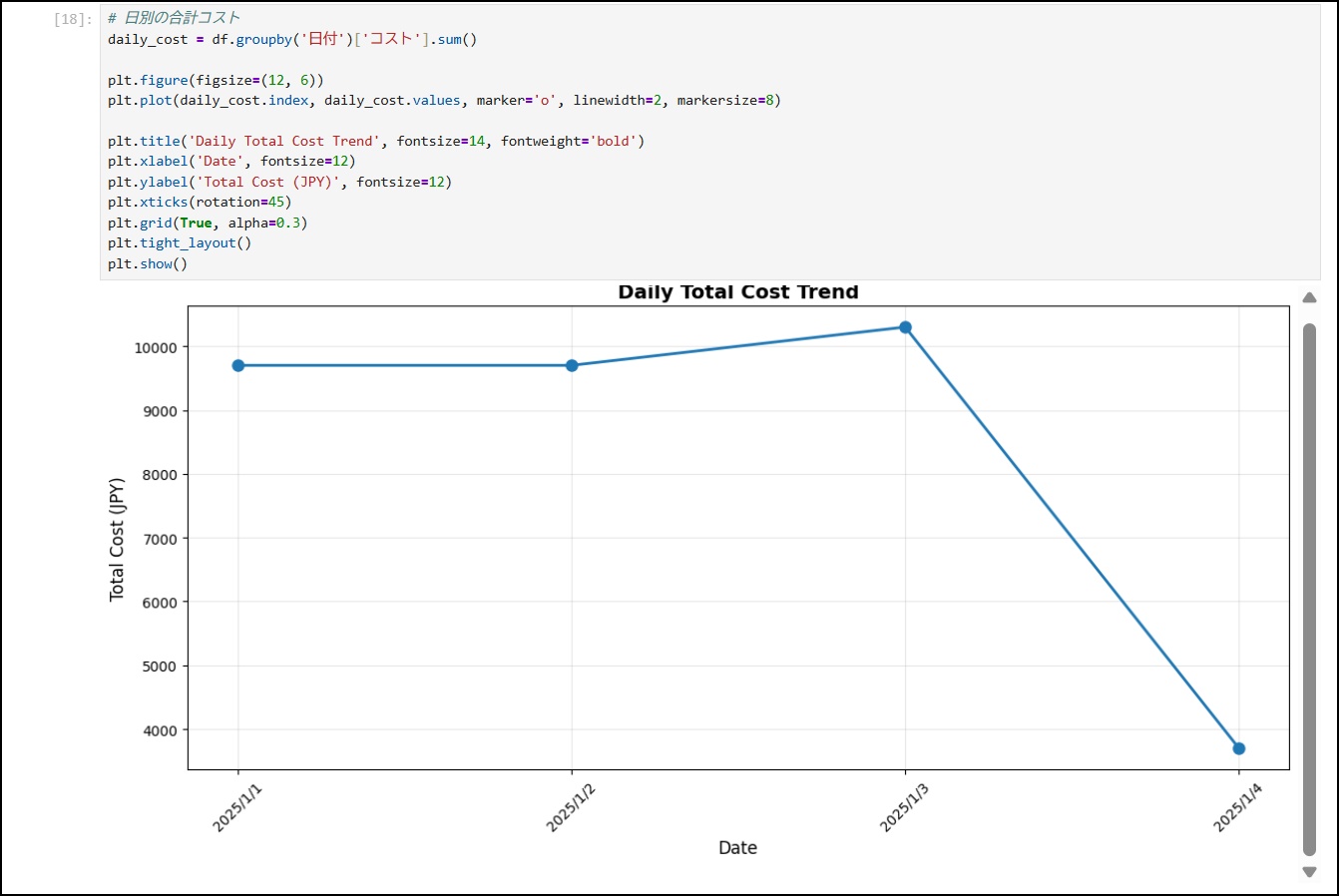
13-11. 日別の積み上げグラフで可視化
# サービス別・日別のピボットテーブル
pivot_data = df.pivot_table(values='コスト',index='日付',columns='サービス名',aggfunc='sum',fill_value=0)
# 積み上げ面グラフ
plt.figure(figsize=(12, 6))
pivot_data.plot(kind='area', stacked=True, alpha=0.7, figsize=(12, 6))
plt.title('Daily Cost by Service (Stacked)', fontsize=14, fontweight='bold')
plt.xlabel('Date', fontsize=12)plt.ylabel('Cost (JPY)', fontsize=12)
plt.legend(title='Service', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.xticks(rotation=45)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()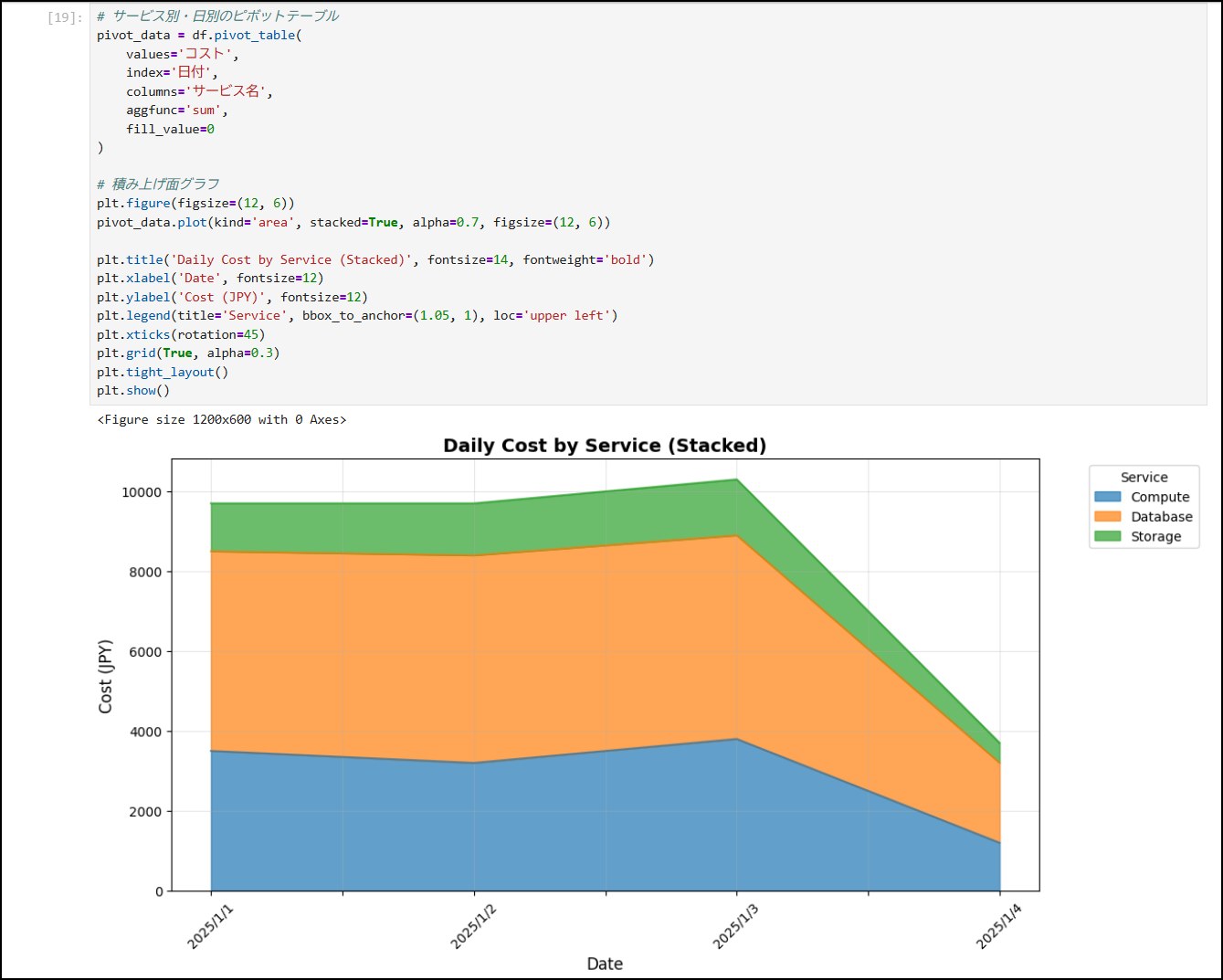
13-12. リージョン別クロス集計
# サービス別・リージョン別のクロス集計
cross_tab = df.pivot_table(values='コスト',index='サービス名',columns='リージョン',aggfunc='sum',fill_value=0,margins=True, # 合計行を追加 margins_name='Total')
print("=== Service x Region Cost Matrix ===")
cross_tab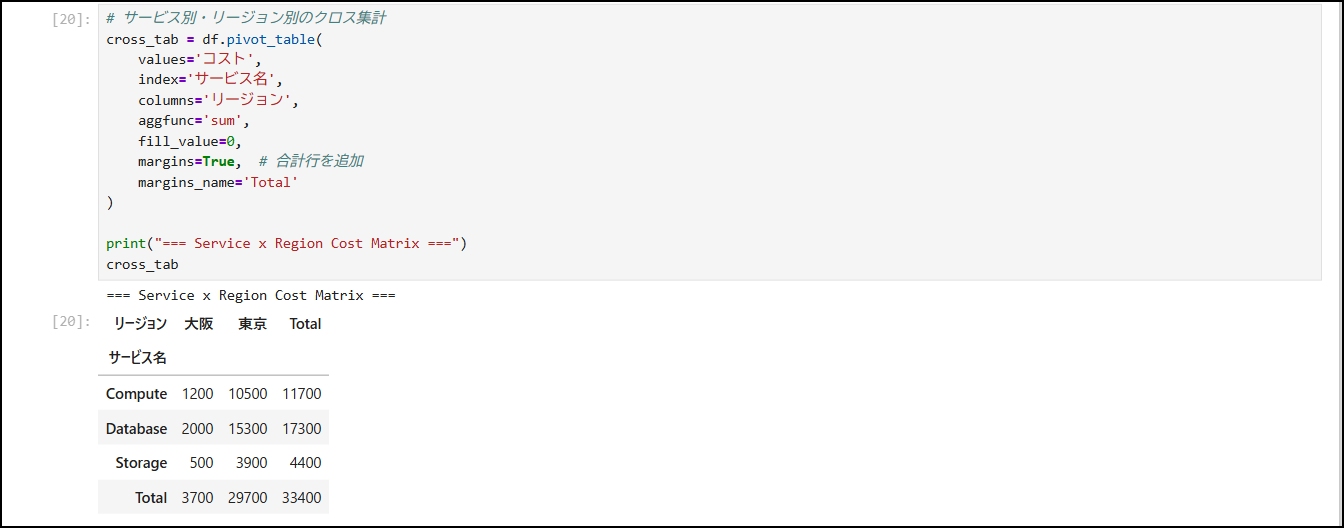
13-13. データのエクスポート
# サービス別集計結果をCSVとして保存
service_total.to_csv('service_summary.csv')
print("service_summary.csv を保存しました")
# ファイルの確認
import os
print(f"保存先: {os.path.abspath('service_summary.csv')}")
# ターミナルで確認cd notebooks/
ls -l
結果: service_summary.csv ファイルが作成されます!
まとめ
構築した環境でできること
| できること | 説明 |
|---|---|
| データ分析 | Pandas、NumPyで高速処理 |
| 可視化 | グラフを数秒で作成 |
| クラウド連携 | Object Storageから直接データ読み込み |
| リモートアクセス | どこからでもブラウザでアクセス |
コスト比較
| 項目 | 従来の方法 | OCI |
|---|---|---|
| 初期費用 | 0円 | 0円 |
| 月額費用 | 1,000円〜 | 0円 |
| データ保存 | ローカルのみ | 20GB無料 |
| スケーラビリティ | PCスペックに依存 | 柔軟に拡張可能 |
⚠️ OCIのAlways Free枠(VM.Standard.E2.1.Microシェイプ、Object Storage 20GBなど)を使用した場合は無料です。Always Free枠を超える場合は従量課金となります。
セキュリティのベストプラクティス
🔒 推奨設定:
✓ SSHキーの安全な管理
✓ 特定IPのみ許可(本番環境)
✓ 強力なパスワード使用
✓ 定期的なシステムアップデート
# 定期的にシステムを更新sudo dnf update -y
# Pythonライブラリも更新pip list --outdated
pip install --upgrade パッケージ名
最後に
この記事では、Jupyter Notebook環境の構築を、実際に手を動かしながら紹介させていただきました。
結論: どこからでもアクセスできるデータ分析環境を構築できました。
これにより、初学者でも挫折せずにデータサイエンスの学習を始められます。
この記事を通じ、皆様のデータ分析学習の一助となれば幸いです。
最後まで読んで頂き、ありがとうございました。
参考リンク
📖 公式ドキュメント
- OCI Documentation: https://docs.oracle.com/ja-jp/iaas/
- Jupyter Documentation: https://jupyter.org/documentation
- Pandas Documentation: https://pandas.pydata.org/docs/