k.sasakiです。前回の記事では、Select AIのワークフローについて理解を深めました。
本記事は Select AIシリーズの第2回として、「Select AIを使わない NL2SQL ワークフロー設計」をテーマにした調査編です。
はじめに
Oracle Autonomous AI Database の Select AIは、LLM を組み合わせて「自然言語 → SQL 生成 → 実行」までをデータベース側で一気通貫に提供する機能です。
ユーザは「やりたいこと(意図)」だけを記述し、スキーマに即した SQL の生成・実行や、結果のチャット出力なども一貫したインターフェースとして扱えます。
一方で、NL2SQL 研究全体を俯瞰すると、典型的なワークフローは「質問理解 → スキーマリンキング(どのテーブル/カラムを使うか)→ 中間表現(IR)設計 → SQL 生成 → 実行・バリデーション・自己修正」といった複数フェーズから構成されており、LLM 時代になってもこのワークフロー自体は有効であることがサーベイペーパーで整理されています。
本記事(調査編)では、以下の3つのソースをインプットに、NL2SQL ワークフローの設計に必要な要素を整理します。
- サーベイペーパーで整理されているNL2SQLのワークフロー
- Select AIの非機能(Verify / Observe / Secure)
- Select AIを使用するシステムのリファレンスアーキテクチャ
この結果を踏まえ、後編の「実装編」では、共有が簡単で、手軽にGUIでワークフローを構築できるGoogle Opal(以下Opal)上で NL2SQL パイプラインを構築し、簡易的にNL2SQLを試すことができるミニアプリを公開します。
また、設計/構築の中で、本記事で整理した各モジュールの実装を試行することで、間接的に、Select AIを使うことでいかに簡単にNL2SQLが実現できるのかという点や、Select AI自体の既存機能でどのように実装できるかを探っていきます。
調査1:NL2SQLのワークフロー
まず、2024年の A Survey of NL2SQL with Large Language Models: Where are we, and where are we going? というサーベイペーパーからNL2SQLのワークフローの構造を見ていきます。
サーベイペーパーのワークフロー
本サーベイペーパーによると、ワークフローは前処理/翻訳処理/後処理の 3 つのフェーズで構成されます。
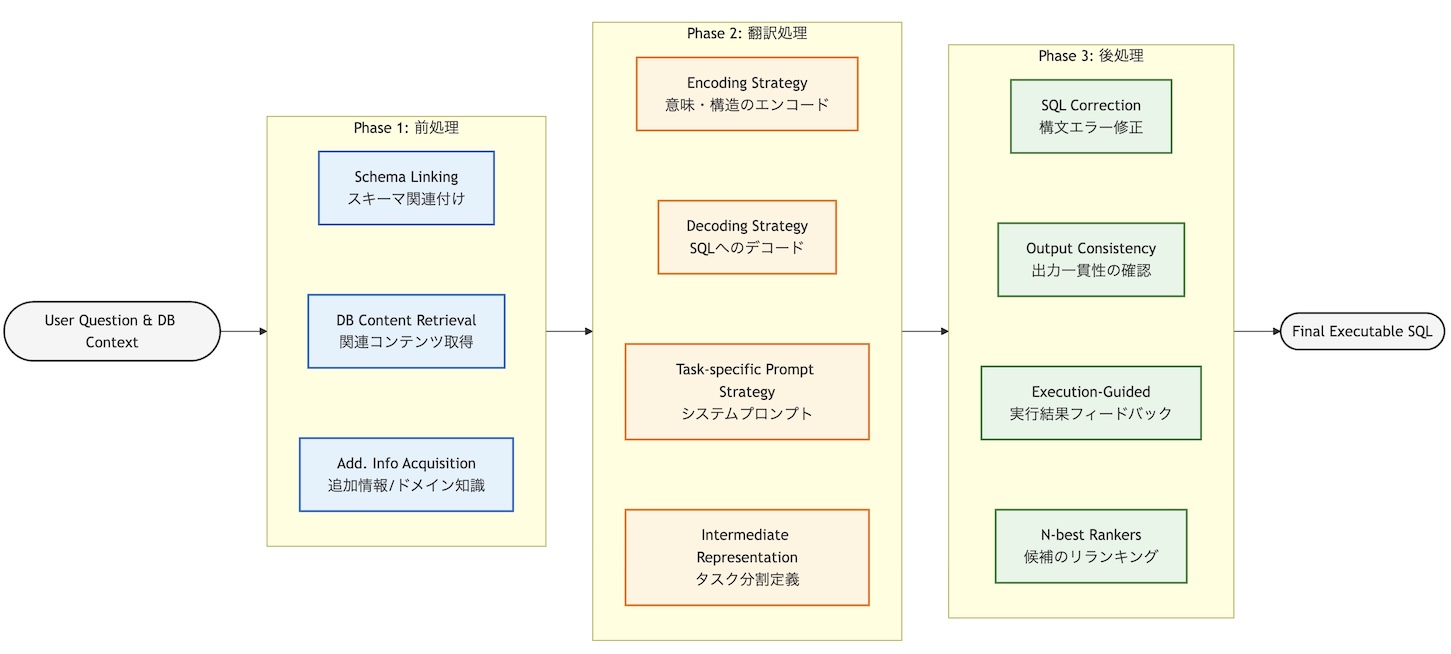
Phase 1: 前処理
前処理はモデルへの入力を整え、NL2SQL で生成される SQL の精度を高める役割を持ちます。
・Schema Linking :ユーザ質問とスキーマを対応付け、関連するテーブル・カラムを特定する。
・Database Content Retrieval : 条件式などに必要となるセル値・レコードなど、問い合わせに関係する DB コンテンツを取得する。
・Additional Information Acquisition :ドメイン知識など追加情報を組み込み、クエリ解釈の文脈を補強する。
Opal での主な実装範囲はこの周辺になると想定しているため、具体的に各モジュールの動作を確認します。
* ユーザの質問
「2023 年のゴールデンウィークに、ちょうど 3 種類の商品カテゴリを購入したお客様の名前を教えてください。」
* テーブル例
`Customer(customer_id, name, status, ...)`
`OrderHeader(order_id, customer_id, order_date, ...)`
`OrderDetail(order_id, product_id, quantity, ...)`
`Product(product_id, category, name, ...)`
Schema Linking がすること
質問文から「どのテーブル・カラムが関係しそうか」を対応付けます。
質問文「2023 年のゴールデンウィークに、ちょうど 3 種類の商品カテゴリを購入したお客様の名前を教えてください。」
* 「お客様の名前」
→ `Customer.name`
* 「購入した」
→ 注文情報 → `OrderHeader` と `OrderDetail`
* 「商品カテゴリ」
→ `Product.category`
* 「2023 年のゴールデンウィーク」
→ 日付条件として `OrderHeader.order_date`
この結果、「今回のクエリには Customer, OrderHeader, OrderDetail, Product テーブルとその中の特定カラムを使う」と特定するのが Schema Linking の役割です。
Database Content Retrieval がすること
次に、スキーマではなく 実データの値 を少しだけ見に行きます。
質問文「2023 年のゴールデンウィークに、ちょうど 3 種類の商品カテゴリを購入したお客様の名前を教えてください。」
* 「ゴールデンウィーク」が何日から何日までかは、システムごとのルール次第です
* 会社の設定テーブル `HolidayRange(name, start_date, end_date)` があれば
* `SELECT start_date, end_date FROM HolidayRange WHERE name = 'GW_2023';`で `2023-04-29` ~ `2023-05-07` を取得しておく。
* 「商品カテゴリ」がどんな値を持っているか
* `SELECT DISTINCT category FROM Product;`で `食品`, `日用品`, `家電`, `書籍` … のような一覧を取り、モデルがカテゴリの扱いを間違えないようにする。
こうして「WHERE order_date BETWEEN '2023-04-29' AND '2023-05-07'」のような具体的な条件を組める準備をします。
Additional Information Acquisition がすること
最後に、「スキーマ+DB の値だけでは足りない日本の業務的な前提・ドメイン知識」を補います。
質問文「2023 年のゴールデンウィークに、ちょうど 3 種類の商品カテゴリを購入したお客様の名前を教えてください。」
* GWの期間をテーブルとして持っていない場合、ゴールデンウィークは「4/29〜5/7」で定義する
* 休眠顧客(`Customer.status = 'INACTIVE'`)は集計対象外とする
* 「商品カテゴリ」は `Product.category` を使う(`Product.subcategory` は別用途)といったルールを外部設定やドキュメントから取得しておき、NL2SQL モデルに渡す。
* 日本特有の呼び方の揺れ
* 「GW」「ゴールデンウィーク」「大型連休」は同じ期間を指す
* こうした表現ゆれを辞書やルールで吸収して、「GW 2023 → GW_2023 の期間」とマッピングする。
Phase 2: 翻訳処理
翻訳処理は、自然言語クエリを SQL 文に変換するパイプラインのコア部分です。
・Encoding Strategy :入力の自然言語と DB スキーマを内部表現に変換し、意味・構造情報をエンコードする。
・Decoding Strategy :内部表現から実行可能な SQL クエリ列へとデコードする。
・Task-specific Prompt Strategy :NL2SQL 用にチューニングされたプロンプトで LLM/PLM を誘導し、変換プロセスを最適化する。
・Intermediate Representation :NL と SQL の間に中間表現を挟み、意味理解とSQL生成の2段階に分けることで、精度を高める。
Encoding StrategyとDecoding Strategyについて、OpalやSelect AIでは汎用LLMを指定するのみなので機能や性能についてはLLMに依存する形になります。
Task-specific Prompt Strategy はいわゆるシステムプロンプトにあたり、「あなたは SQL 専門家です。以下の DB スキーマに対して、日本語の質問を 1 本の SQL クエリに変換してください。SQL 以外は出力しないでください。」といった指示や、Few-shotでいくつかSQL文を入れることで、LLMには手を加えずに出力結果をコントロールする部分です。
Phase 3: 後処理
後処理は生成済み SQL をユーザ期待により近づけるための仕上げフェーズとして機能します。
・SQL Correction Strategies :生成 SQL の構文エラーや明らかな間違いを検出し修正する。
・Output Consistency :複数サンプルを生成し、一貫性が高い結果を選ぶことで安定した出力を得る。
・Execution-Guided Strategies :SQL を実行し、その結果をフィードバックとして利用し、後続の修正・改善を行う。
・N-best Rankers Strategies :モデルの上位候補群(N-best)をリランキングし、より正確なクエリを選択する。
翻訳処理で生成したSQLをそのまま出すのではなく、検証したり、複数回実行や複数候補からの選択をすることやフィードバックを通して、より安定したSQLを生成可能とするという構成です。
以上が、サーベイペーパーから確認できた、NL2SQLのワークフローとなります。
調査2: Select AIの非機能
次に、Oracle Blog: Verify, Observe, and Secure your Generative AI usage with Oracle Autonomous AI Database Select AIから、Select AIを本番運用するにあたり考慮すべきセキュリティや可視性などに、どのように対処しているかを見ていきます。
Select AIを本番運用するために必要な3つの柱
この記事では、Select AIは、NL2SQLを含む生成AI利用における「正しさの検証」「利用状況の可視化」「セキュリティとガバナンス」を、データベース側の機能として一体的に提供することで、実運用上の課題を解消しようとしていることがわかります。※図は記事上の分類をまとめたもので各機能の呼称などは一部変換しています。
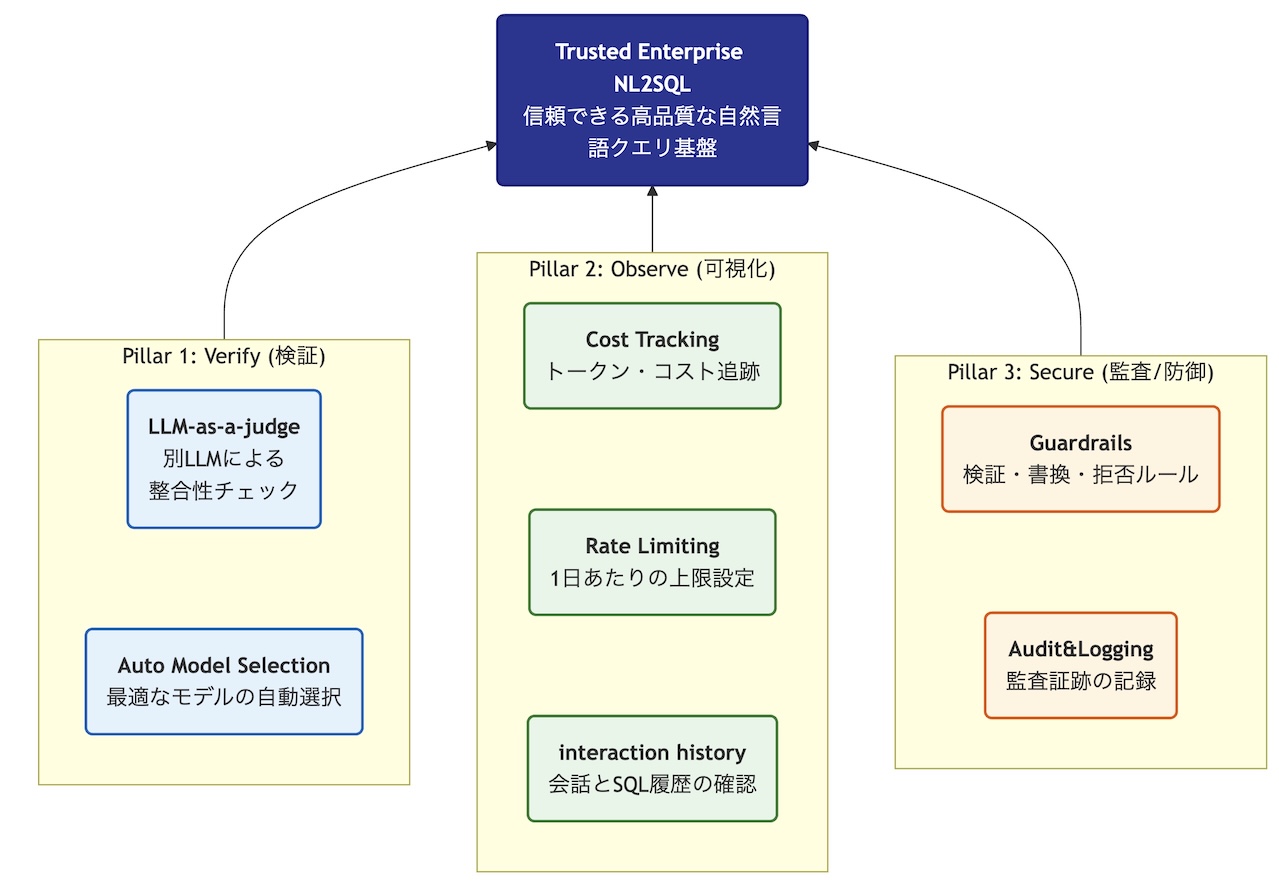
調査1のワークフローでも出てきた、生成されたSQLの検証に加えて、可視化やセキュリティなど、Select AIに本番運用を想定した機能や構成が考慮されていることがわかります。
VerifyのLLM-as-a-judgeやAuto Model Selectionなど、一部の機能は2026年1月時点で Select AIの機能としては盛り込まれていないようですので、今後の実装予定や、Select AIの外側での構成するブロックの可能性があります。
調査3: Select AIリファレンスアーキテクチャ
最後に、先日公開された、Select AIとOracle APEXを使用して、エージェント的で忠実度の高い会話型AIフレームワークを構築から、リファレンスアーキテクチャ上のワークフローの定義に注目して見ていきます。
リファレンスアーキテクチャのワークフロー
図はドキュメントに記載のワークフローを日本語化し、縦に引き伸ばして流れを見やすくしたものです。
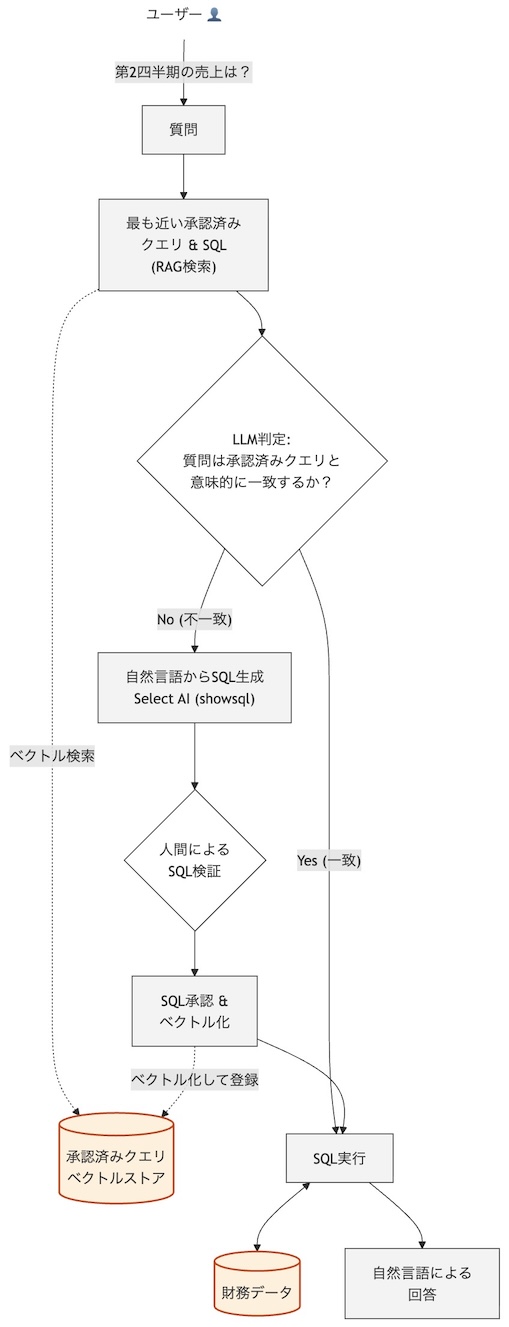
ワークフローの分析
まず、Select AIの使用箇所に注目すると、SELECT AI showsqlを使い、Select AIの外側で人間によるSQL検証フェーズを設けています。
人間によるSQLの検証の結果がOKであれば、承認されたSQLとして、承認済みクエリベクトルストアに保存され、次回以降質問を受けた際に、質問を承認済みクエリベクトルストアと照合し、、意味的に一致するSQLが存在した場合は、SQLの生成を行わず、そのまま承認済みクエリを実行するという方式です。
人間によるSQLの検証の結果がNGの場合の経路の記載がありませんが、最終的には、質問者からの再試行を促す挙動となると思われます。
本アーキテクチャはSQL生成を使用しない経路をつくることで、一貫して安全なSQL文の提供やトークンの消費を削減できるアーキテクチャとなっています。
注意が必要なのは、Select AIをそのまま使用する場合と比較すると、余分にベクトル検索が走るため、ここでもベクトル化にLLM問い合わせが発生する点や、承認済みのSQLへのベクトル検索精度が高いことを前提としているため、単にSelect AI単体を使うより、考慮するポイントが増える点です。
また、人間による検証を入れていますので、業務データやSQLに知識のある人が利用する分にはそのままチェック可能なので、単純な手間の削減にはなりますが、それらの知識を持たない現場などで使用することを想定した場合、最終的にはSQLを検証できる人を増やすなり、 SELECT AI explainでSQLの内容を噛み砕いた説明を表示することや、LLM やルールベースの自動検証をつけるなどの考慮も必要になります。
単に動的にSQLを生成するだけではなく、さらにデータを活用するということも視野に入れるのであれば、ある程度業務データが格納されたテーブルの構造や、どこにどの情報が入っているのかという情報を利用者が知っておくことが、ツールとしてSelect AIを活用することが可能です。NL2SQLという技術全体が、そういった知識を展開するためのハードルを下げたり、きっかけとなる一面があると考えています。
まとめ
本記事では、まず、サーベイペーパーをもとに、NL2SQL の一般的なワークフローが「前処理→ 翻訳処理→ 後処理」というフェーズで構成されており、どのようなモジュールが存在するのかを調査しました。
あわせて、Oracle Select AIが Verify / Observe / Secure などの非機能を通じて、NL2SQL を本番環境で安全かつ継続的に運用するための仕組みや、リファレンスアーキテクチャのワークフローからより安全に一貫してSelect AIを使うためのアーキテクチャを調査しました。
これらの知見をベースに、次回の実装編では Google Opal 上に NL2SQL ワークフローを構築し、本記事で整理した各モジュールをどこまでワークフローとして具体化できるか、また Select AIがどのレイヤをどの程度まで抽象化してくれているのかを、実際の動作を通して検証していきます。