
k.sasakiです。本記事はOracle Cloud Infrastructure Advent Calendar 2025のDay24の記事です。
今年は 2025 Oracle AI選手権に出場する機会をいただき、SELECT AIに本格的にふれて検証する機会に恵まれました。
SELECT AIは知れば知るほど、Oracle Databaseがこれまで実装してきた機能がうまく連携された非常にすぐれたアーキテクチャであると実感します。
本日は SELECT AI Insights #1と題しまして、SELECT AIのチュートリアルで触れられているAIプロファイルという要素を深掘りしていきます。
目次
はじめに
本記事は、Oracle公式のSELECT AIチュートリアルを終えた方に向けた「次の一歩」となる記事です。
チュートリアルでは、SELECT AIを使って自然言語でデータを取得する方法を学びました。実際に動かしてみると「すごい、本当に動く!」という感動があったのではないでしょうか。
しかし、こんな疑問も浮かんだかもしれません。
- 自然言語がSQLに変換される裏側では、何が起きているのか?
- AIプロファイルの設定項目は、それぞれ何を制御しているのか?
- コメントを追加したら結果が変わったけど、なぜ?
本記事では、チュートリアルの内容をベースに、SELECT AIの内部ワークフローと、その動作を制御するAIプロファイルについて深掘りしていきます。
「動かし方」を知った次は、「動く仕組み」を理解する。それによって、SELECT AIをより効果的に活用できるようになるはずです。
SELECT AI の基本的な動きを確認する
まずは、OCIチュートリアル「SELECT AIを試してみる」の内容をもとに、基本的な動作を確認していきましょう。
このチュートリアルでは、ニューヨークの高校情報が格納されたテーブルに対して、highschools_viewというビューを通じてSELECT AIからアクセスするという操作を行っています。どのテーブルにアクセスを可能にするか、どの大規模言語モデル(LLM)を使用するかといったオプションはAIプロファイルで事前に設定可能となっており、用途やユーザーの権限に応じて使い分けることができます。
なお、SELECT AI '自然言語'とした場合はSELECT AI runsql '自然言語'と同じ動作となり、SQLの生成から実行、結果取得までが行われます。一方、SELECT AI showsql '自然言語'とした場合は、SQLの生成で停止し、SQL文が結果として返されます。
高校は全部で何校ありますか
-- セッションで使用するAIプロファイルを指定
EXEC DBMS_CLOUD_AI.SET_PROFILE('GENAI_COHERE_COMMAND_R');
-- 高校の総数を質問
SELECT AI 高校は全部で何校ありますか;
-- Result
427
-- 直接SQLで確認
SELECT COUNT(*) FROM highschools_view;
-- Result
427
highschools_view内には427校分のデータが格納されており、SELECT AIを経由した問い合わせと、SQLを直接実行した結果が一致することがわかります。
マンハッタン市内に高校は全部で何校ありますか(コメントなしの場合)
次に、もう一つ条件を追加した問い合わせを試してみます。
-- マンハッタン市内の高校数を質問
SELECT AI マンハッタン市内に高校は全部で何校ありますか;
-- Result
0
実際にはニューヨークのマンハッタン地区にも高校はあるはずなので、期待した結果とは異なります。そこで、showsqlコマンドを使用して生成されたSQLを確認してみましょう。
-- 生成されたSQLを確認
SELECT AI showsql マンハッタン市内に高校は全部で何校ありますか;
-- Result
SELECT COUNT(*) AS MANHATTAN_HIGH_SCHOOLS
FROM "SELECT_AI_USER"."highschools_view"
WHERE BOROUGH = 'Manhattan'
BOROUGHは高校の所在地区情報を持つ列です。一見問題なさそうに見えますが、実際のデータは'マンハッタン'とカタカナで格納されていたため、'Manhattan'という条件に一致せず、検索結果が0件になってしまいました。
マンハッタン市内に高校は全部で何校ありますか(コメントありの場合)
続いて、BOROUGH列にデータがカタカナで格納されているという情報をコメントとして付与して、コメントまでLLMに送信して再度問い合わせてみます。
-- 列にコメントを追加
COMMENT ON COLUMN highschools_view.BOROUGH IS '高校が所在する地区。カタカナで地区名が格納されています。';
-- コメント送信を有効にした新しいAIプロファイルを作成
BEGIN
DBMS_CLOUD_AI.CREATE_PROFILE(
'GENAI_COHERE_COMMAND_R_COMMENTS',
'{
"provider": "oci",
"credential_name": "OCI_GENAI_CRED",
"model": "cohere.command-r-08-2024",
"oci_apiformat": "COHERE",
"region": "ap-osaka-1",
"comments": "true",
"object_list": [
{"owner": "select_ai_user", "name": "highschools_view"}
]
}'
);
END;
/
-- 新しいプロファイルを有効化
EXEC DBMS_CLOUD_AI.SET_PROFILE('GENAI_COHERE_COMMAND_R_COMMENTS');
-- 再度質問
SELECT AI マンハッタン市内に高校は全部で何校ありますか;
-- Result
107
-- 生成されたSQLを確認
SELECT AI showsql マンハッタン市内に高校は全部で何校ありますか;
-- Result
SELECT COUNT(*) AS manhattan_highschools_count
FROM "SELECT_AI_USER"."HIGHSCHOOLS_VIEW"
WHERE BOROUGH = 'マンハッタン'
無事、WHERE句の条件がカタカナの'マンハッタン'に変化し、意図通りのSQLが生成されました。
SELECT AIがもたらすメリット
チュートリアルから見えてくるSELECT AIのメリットは以下の3点です。
SQLの知識がなくてもデータを取得できる
従来、SQLでデータを取り出すにはテーブルやビューを指定し、列や条件を付与するという文法の技術的な知識が必要でした。SELECT AIでは、この知識がなくても欲しいデータを取得できることがよくわかります。
格納データの知識がなくてもデータを取得できる
SQLでデータを取り出す際には、どのテーブルに何があるのか、格納されているデータの形式などのシステム固有の知識が必要でした。しかし、たとえば、BOROUGH列にはカタカナのデータが格納されているという情報をコメントで事前に付与しておくなど、テーブルのメタデータを増やすことで、利用者はデータの詳細を知らなくても欲しいデータを取得できるようになります。
目的を指定するだけでデータを取得できる
もう一つ特徴的なのは、「欲しいデータを指定する」という目的指定型のインターフェースが実現されている点です。
従来のアプリケーションでも、SQL文を隠蔽して検索キーワードや条件を指定する形式は存在しましたが、結局はどのテーブルに何のデータが入っているかという知識は必要でした。SELECT AIでは、以下のように欲しいデータを指定することで、LLMがDDLやコメントなどのメタデータを参照して、適切なSQL文を生成してくれます。
SELECT AI マンハッタン市内に高校は全部で何校ありますか;
自然言語で目的を指定してデータベースから必要な情報を取得する、という行為そのものが、Oracle Select AI をはじめとした NL2SQL(自然言語からSQL文を生成する技術)の目指すところです。
SELECT AI の仕組み
ここからは、チュートリアルの内容をもとにSELECT AIのshowsqlアクションがどのようなワークフローで実現されているかを考察していきます。
※ SELECT AI内部のワークフローは公開されていないため、基本的な動作をもとに組み立てた推定である点にご注意ください。
showsqlのシンプルなワークフロー
まずは、最も基本的なSELECT AI showsqlの処理の流れを追ってみましょう。ユーザーが自然言語プロンプトを入力してからSQLが返ってくるまでの処理フローは、以下のステップで構成されていると考えられます。
-
ユーザープロンプトの入力
ユーザーがSQL Developerなどのクライアントツールから、SELECT AI showsql '自然言語';という形式でコマンドを実行します。 -
AIプロファイル参照
AIプロファイルを参照し、アクセス先のLLM、LLMへ送るメタデータの設定情報を取得します。 -
メタデータの取得
LLMがSQL文を生成するための「文脈」を構築します。スキーマ情報やテーブル/ビューの列情報、コメントなどのメタデータを参照し、欲しいデータを取得するためのSQLを生成する準備をします。 -
LLMへのリクエスト構築
ユーザープロンプト、メタデータ、システムプロンプトを組み合わせて、LLMの能力を最大限に引き出すための最適化されたプロンプトを動的に生成します。 -
LLMによるSQL文生成
リクエストを受け取ったLLMは、与えられた文脈情報に基づいて最適なSQL文を生成します。 -
ユーザーへSQL文の表示
LLMから返されたSQL文が、ユーザーの画面に表示されます。
チュートリアルで実行された流れをそのままステップ単位で記述したシンプルなワークフローです。実際にはもっと複雑でしょうが、感覚的な理解とは一致するはずです。
LLMを使用した機能としては、ステップを分けたりシステムプロンプトを調整したりする手段もありますが、システムプロンプトを与える機能は提供されておらず、内部のワークフローは隠蔽されています。そのため、現時点ではワークフローのプロセスとしての調整はSELECT AIでは不可能となっています。
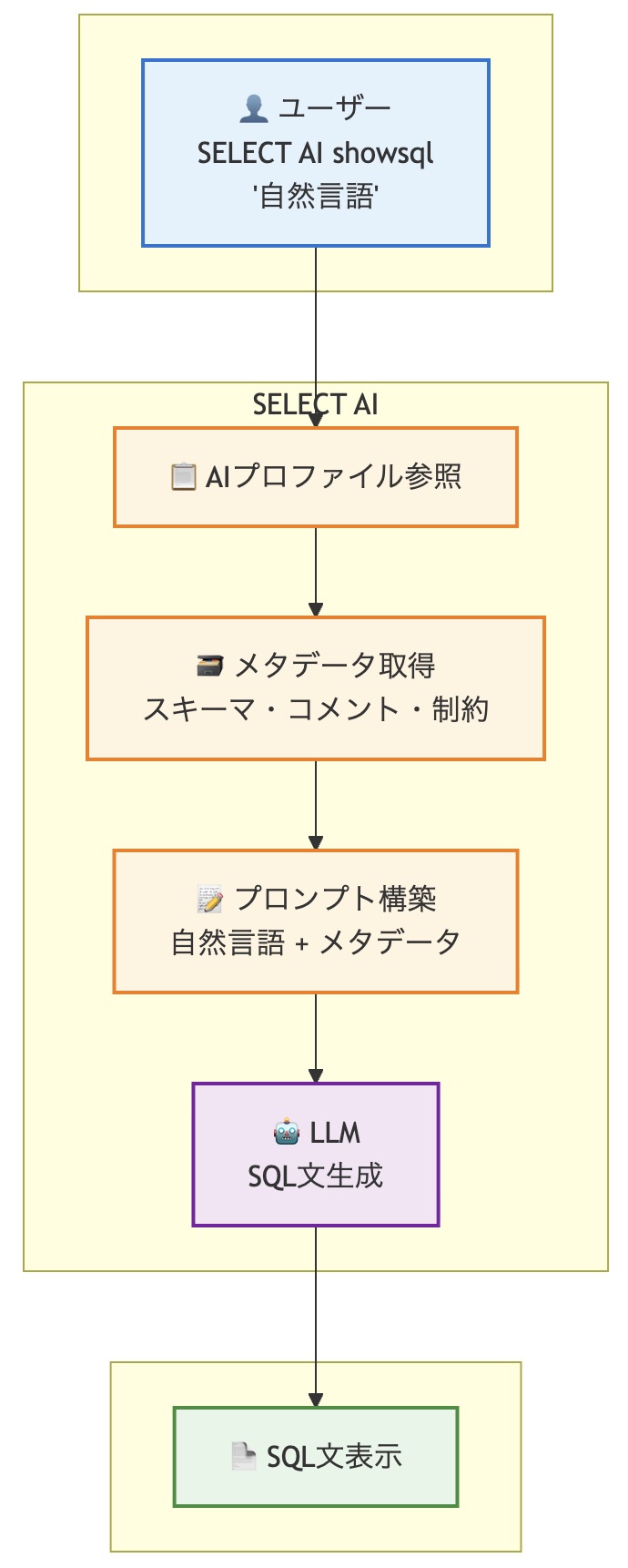
精度と文脈の鍵:「AIプロファイル」によるワークフローの拡張
SELECT AIの動作を理解するための鍵となるのが、チュートリアルでも定義していたAIプロファイルです。
-- チュートリアルから再掲
BEGIN
DBMS_CLOUD_AI.CREATE_PROFILE(
'GENAI_COHERE_COMMAND_R_COMMENTS',
'{
"provider": "oci",
"credential_name": "OCI_GENAI_CRED",
"model": "cohere.command-r-08-2024",
"oci_apiformat": "COHERE",
"region": "ap-osaka-1",
"comments": "true",
"object_list": [
{"owner": "select_ai_user", "name": "highschools_view"}
]
}'
);
END;
/
Oracleはこのオブジェクトを単なる接続設定ファイルとしてではなく、アーキテクトがコスト、パフォーマンス、精度をバランスさせるための「ポリシーおよびコンテキスト定義オブジェクト」として定義しました。LLMとの対話の質を向上させるための「司令塔」として機能し、基本ワークフローに重要な「分岐」と「情報の追加」をもたらしてくれます。
AIプロファイルの主要な属性
AIプロファイルで設定できる主要な属性について解説します。
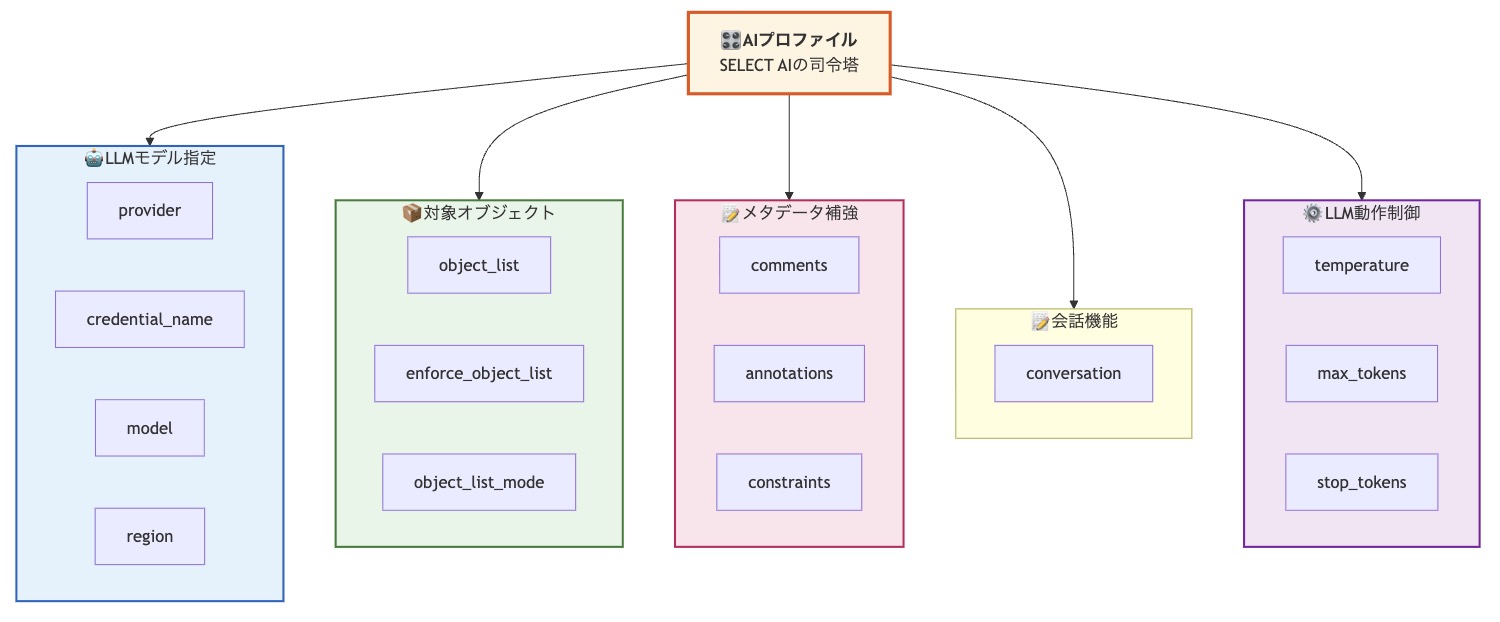
LLMモデル指定用の属性
| 属性名 | 説明 | デフォルト値 |
|---|---|---|
provider |
AIプロバイダーを指定(oci, openai, azure, cohere, google, anthropic, awsなど) |
(必須) |
credential_name |
AIプロバイダーAPIへの認証情報名 | (必須) |
model |
使用するAIモデル名 | プロバイダーごとのデフォルト |
region |
OCIのLLMエンドポイントのリージョン | us-chicago-1 |
oci_apiformat |
OCI専用クラスタでのAPIフォーマット(COHERE, GENERIC) |
- |
対象オブジェクトに関する属性
| 属性名 | 説明 | デフォルト値 |
|---|---|---|
object_list |
SQL変換対象のテーブル/ビューをJSON配列で指定 | - |
enforce_object_list |
object_listのオブジェクトのみに制限するか |
false |
object_list_mode |
メタデータ送信範囲(automated: 関連テーブルのみ / all: すべて) |
all |
enforce_object_list がfalseの場合、AIプロファイルに指定されたオブジェクトではなく、ユーザがアクセスできるオブジェクトにアクセス可能となります。
-- プロファイルの存在するスキーマのベクトルインデックスを出力するSQL
SELECT * FROM user_cloud_vector_indexes;
-- Results (tsvファイルから貼り付け)
"INDEX_ID" "INDEX_NAME" "STATUS" "DESCRIPTION" "CREATED" "LAST_MODIFIED" "ORACLE_MAINTAINED"
20 "GENAI_COHERE_COMMAND_R4_OBJECT_LIST_VECINDEX" "ENABLED" "Automated vector index for object list" 2025-12-23 07:32:26.775480000 UTC 2025-12-23 07:32:26.775480000 UTC "N"
メタデータ補強に関する属性
| 属性名 | 説明 | デフォルト値 |
|---|---|---|
comments |
テーブル/カラムのCOMMENT情報をLLMに送信するか | false |
annotations |
26aiのアノテーション機能を活用するか | false |
constraints |
主キー/外部キーなどの制約情報をLLMに送信するか | false |
日本語環境ではcommentsをtrueに設定し、カラムに日本語の説明を付けておくことで、日本語の質問に対して正確なSQLを生成しやすくなります。
会話機能に関する属性
| 属性名 | 説明 | デフォルト値 |
|---|---|---|
conversation |
会話履歴を有効にするか(直近10件程度を文脈として使用) | false |
trueに設定すると、「2024年の売上は?」→「では、2023年は?」のような文脈を維持した対話が可能になります。ただし、トークン使用量が増加するためコストとのバランスに注意してください。
LLM動作制御に関する属性
| 属性名 | 説明 | デフォルト値 |
|---|---|---|
temperature |
出力のランダム性(0〜1、低いほど一貫性重視) | - |
max_tokens |
生成トークン数の上限 | 1024 |
stop_tokens |
出力を終了させるトークン(例: [";"]) |
- |
メタデータ設計のポイント
AIプロファイルのオプションでLLMに渡すメタデータを選択できるため、いかに質の良いメタデータを付与するかがSELECT AIの性能向上に直結します。外部キー制約の定義や、AIにもわかりやすい列名の設計といったDDL的な要素を見直すことが効果的です。
ただし、テーブル自体に用途ごとに大量のコメントを付与してしまうと、そのテーブルが特定の目的でしか使用できなくなる可能性があります。また、object_listで指定するテーブルが多く、似たテーブル名や列名が増えると、メタデータがノイズになる可能性もあります。
そこで、以下のプラクティスをお勧めします。
- AIプロファイルを用途ごとに分割し、切り替えて利用する
object_listで参照可能にするオブジェクトは必要最小限に抑える- 元のテーブルではなくビューを利用してコメントを付与し、データとコンテキストの結合度を下げる
まとめ
本記事では、SELECT AIのshowsqlコマンドを題材に、自然言語からSQL変換が行われる裏側の仕組みを考察してきました。
SELECT AIは、SQLの知識がなくても、また格納データの詳細を知らなくても、自然言語で目的を伝えるだけでデータを取得できるという革新的な機能です。その動作の鍵となるのがAIプロファイルであり、LLMモデルの選択、対象オブジェクトの指定、メタデータの補強といった設定を通じて、SQL生成の精度やコストをコントロールすることができます。
また、ワークフロー自体に手を加えるのではなく、独立したAIプロファイルというオブジェクトで動作を調整できる設計は、運用の柔軟性という点で非常に優れています。用途やユーザーに応じてプロファイルを切り替えるだけで、同じSELECT AIの仕組みを様々なシーンに適用できるのです。
おわりに
最後までお読みいただき、ありがとうございました。
SELECT AIは、データベースと生成AIの融合という新しい領域において、Oracleがいち早く実用的な機能としてリリースしたものです。単なる技術デモではなく、エンタープライズでの利用を見据えた設計思想が随所に見られる点は、データベースベンダーとしてのOracleの経験と技術力の賜物といえるでしょう。
SELECT AIは今後もさらに進化を続けていくことが予想されます。ぜひ皆さんも実際に触ってみて、その便利さと奥深さを体験してみてください。
今後も、SELECT AIに関する記事について深掘りしていきたいと思います。