
※このブログは2023年12月時点の情報に基づいて作成されているため、現在の状況と異なる可能性がございます。
こんにちは。k.otsukaです。
Oracle Cloud Infrastructure Advent Calendar 2023のDay8記事です。
アップデートと新機能のリリースが早くなかなか追い付くことができないMDS(Mysql Database Service)ですが、7月下旬より、HeatWaveを有効化した後にオプションとしてLakehouse機能が使える"MySQL HeatWave Lakehouse"がリリースされました。(記事執筆までだいぶ経ってしまいましたが。。)
本機能に関するOracle社公式ウェビナーで得た情報や注意点などをおさらいしつつ、本機能についてざっくりと紹介していこうかと思います。
MDSについてやHeatWaveについては過去の記事の中で紹介しているので、そちらも合わせてご覧ください。
【過去記事】
・Oracle Cloud(OCI)ついにPaaSのMySQL(MySQL Database Service)が登場!
・Oracle Cloud MDS(MySQL)にHA構成が登場!
・Oracle Cloud MDS (MySQL Database Service)のHeatWave機能を検証しました!
・OCI MySQL Database Service(MDS)でリージョン間レプリケーションを構成する
目次
MySQL HeatWave Lakehouseの魅力
1.Lakehouseの機能として、オブジェクトストレージ上にCSVファイルやParqustファイルを置くだけで、そのデータをロードしつつテーブルを作成することができます。
※オブジェクトストレージに置いたデータを直接分析することは現時点ではできません。(そういった機能も今後のアプデに含まれているみたいです!)
※Jsonファイルも今後のアップデートで利用できるようになるみたいです!
2.HeatWaveクラスタ上に本テーブルが作成されるため、高速なデータ分析が可能になります。他社サービス比較は行えておりませんが、データロードは最大9倍、クエリ実行時間は最大36倍の速さで実行することができるようです。(一部引用)
500 TB TPC-H* ベンチマークでは、「MySQL HeatWave Lakehouse」のクエリ性能が次のように実証されています。
Amazon Redshiftと比較して9倍高速
Snowflakeと比較して17倍高速
Databricksと比較して17倍高速
Google BigQueryと比較して36倍高速
「MySQL HeatWave Lakehouse」でオブジェクト・ストアからのデータをロードする際の性能は、以下の通りです。
Amazon Redshiftと比較して9倍高速
Snowflakeと比較して2倍高速
Databricksと比較して6倍高速
Google BigQueryと比較して8倍高速
MySQL HeatWave Lakehouseの注意点
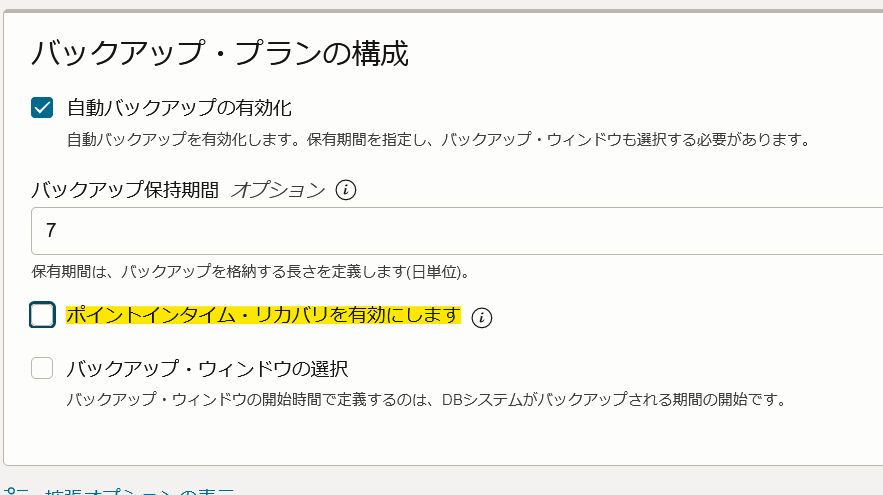
1."ポイントインタイムリカバリ機能"及び"HA構成"のMDSに対応していないため、現時点ではご利用中のMDSに本機能を加えるというよりは、Lakehouse用にMDSを構築する必要があります。ポイントインタイムリカバリについてはMDS構築時デフォルトで有効化されているため、本機能を使用する際は無効化を心掛けましょう。
※この件も近日中には対応予定みたいです。
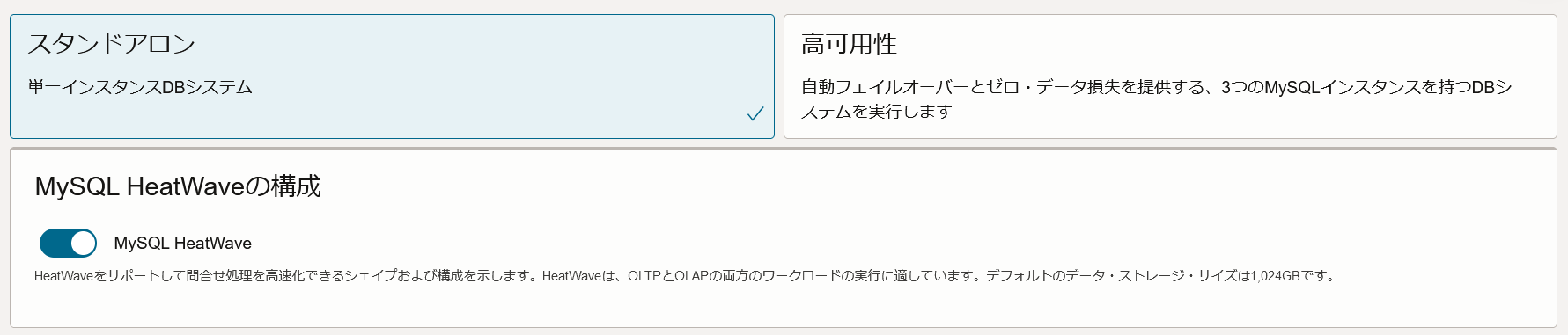
2.初期構築の段階ではLakehouse機能を有効化することができません。MDS構築後にHeatWaveクラスタの編集画面から有効化する必要があるのでご注意ください。
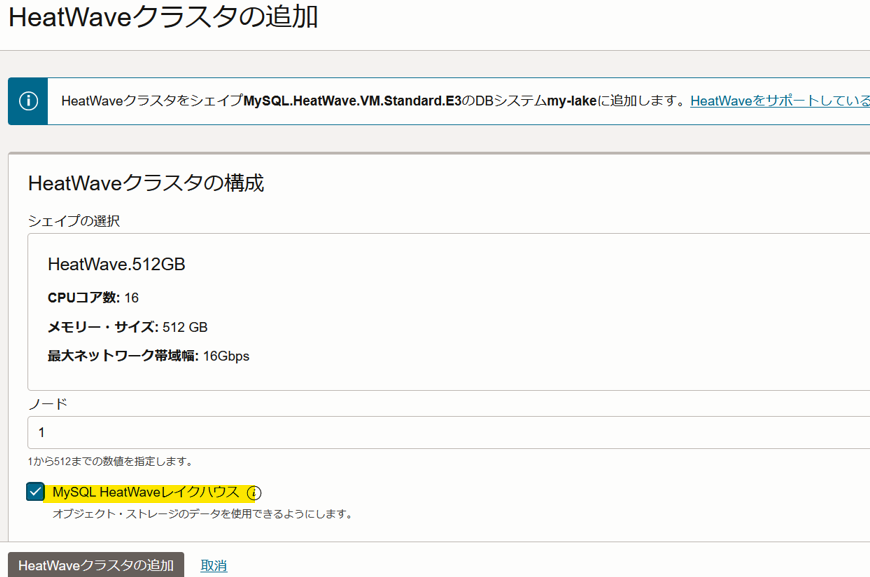
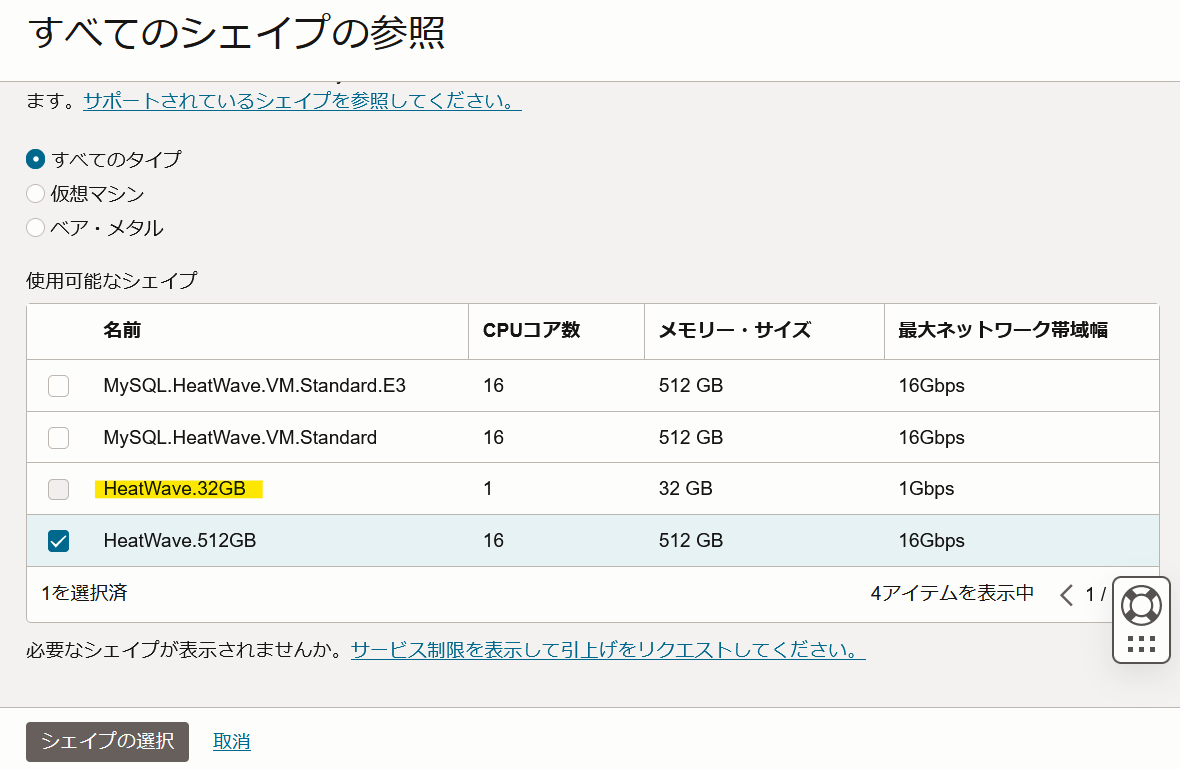
3.HeatWaveクラスタを小さいHeatWaveシェイプで作成した場合は本機能を有効化することができません。本機能を利用する際は従来の高性能シェイプを使用してHeatWaveクラスタを作成する必要があるのでご注意ください。
Lakehouse機能の費用
Lakehouseは「MDS本体」と「Heatwave有効化」が必要となります。
そのため利用するまでのコストハードルが若干高いように感じられるかと思います。Lakehouse機能自体は安く利用できるのですが、、。
以下参考までに50GBの容量で作成した場合の料金を紹介します。
参考:https://www.oracle.com/jp/mysql/#lakehouse
| リソース | 50GB利用する場合(2023/12/8現在) |
| MDS(1VM) | 37,110円 |
| Heatwave(512GB/mem) | 36,664円 |
| Lakehouse | 140円 |
実際に使ってみる
紹介した注意点を考慮しつつ、実際にLakehouse機能を使ってみます。事前準備として、オブジェクトストレージに"東京都が提供している人口に関するデータ"をアップロードしておきました。
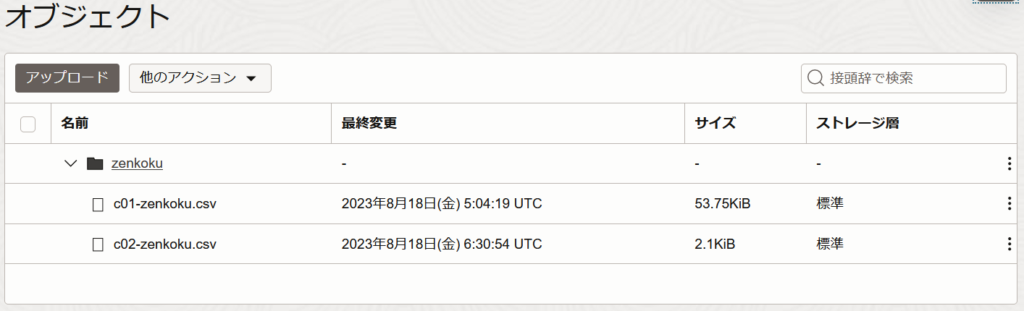
オブジェクトストレージへのアクセス権限を付与
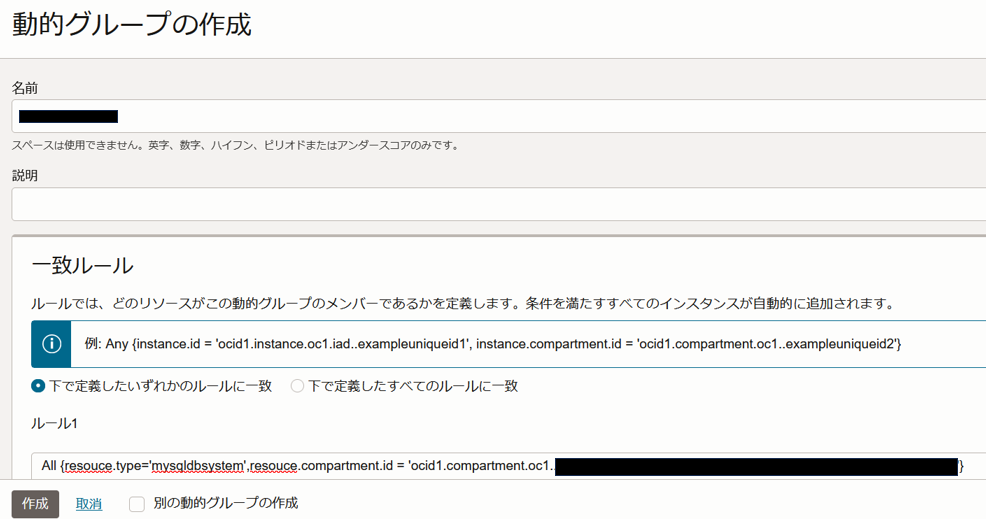
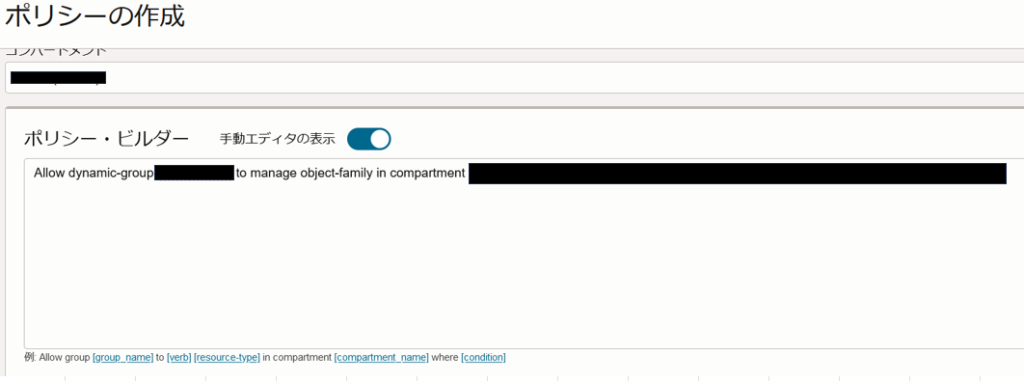
MDSがオブジェクトストレージにアクセスするための権限を付与します。PARリクエストを利用する方法とリソースプリンシパルを利用する方法の2種類ありますが、本番用途では継続的にLakehouse機能を利用することが多いと思うので、リソースプリンシパルを利用してLakehouse機能を試してみます。
1.MDSが所属しているコンパートメントを動的グループに登録
2.動的グループにオブジェクトストレージ(object-family)のmanage権限を付与
読み込んでみる
MDSにデータベースを作成します。
mysql> create database lakehouse_db;
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| lakehouse_db |
| mysql |
| mysql_audit |
| performance_schema |
| sys |
+--------------------+
手動で読み込む
手動で読み込ませる場合、CSVファイルのカラム名に従って事前にテーブルを作成しておく必要があります。また、CREATE文と同時に読み込み用の構文も同時に実行します。
CREATE TABLE LAKETABLE (
都道府県コード int NOT NULL,
都道府県名 varchar(255) NOT NULL,
元号 varchar(255) NOT NULL,
和暦_年 int NOT NULL,
西暦_年 int NOT NULL,
注 varchar(255),
人口_総数 bigint NOT NULL,
人口_男 bigint NOT NULL,
人口_女 bigint NOT NULL,
PRIMARY KEY (都道府県コード, 和暦_年)
) ENGINE=lakehouse
ENGINE_ATTRIBUTE='{
"file": [
{
"namespace": "【namecpace名】",
"region": "ap-tokyo-1",
"bucket": "bucket-lake",
"prefix": "zenkoku/c01-zenkoku.csv"
}
],
"dialect": {
"format": "csv",
"is_strict_mode": false,
"field_delimiter": ",",
"record_delimiter": "\\n"
}
}';
テーブルに対してHeatWaveで読み込ませる設定と、対象テーブルのロードを行います。
mysql> ALTER TABLE LAKETABLE SECONDARY_ENGINE = RAPID;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> ALTER TABLE LAKETABLE SECONDARY_LOAD ;
Query OK, 0 rows affected, 31 warnings (4.00 sec)
「ALTER TABLE LAKETABLE SECONDARY_LOAD」を実行したタイミングで、オブジェクトストレージにアップロードしていたCSVファイルをHeatWaveに配置したテーブルに抽出されます。
mysql> select * from LAKETABLE;
+-----------------------+-----------------+--------+------------+------------+------+---------------+------------+------------+
| 都道府県コード | 都道府県名 | 元号 | 和暦_年 | 西暦_年 | 注 | 人口_総数 | 人口_男 | 人口_女 |
+-----------------------+-----------------+--------+------------+------------+------+---------------+------------+------------+
| 0 | | | 0 | 0 | | 0 | 0 | 0 |
| 0 | | | 9 | 1920 | | 55963053 | 28044185 | 27918868 |
| 1 | | | 9 | 1920 | | 2359183 | 1244322 | 1114861 |
| 2 | | | 9 | 1920 | | 756454 | 381293 | 375161 |
| 3 | | | 9 | 1920 | | 845540 | 421069 | 424471 |
| 4 | | | 9 | 1920 | | 961768 | 485309 | 476459 |
| 5 | | | 9 | 1920 | | 898537 | 453682 | 444855 |
| 6 | | | 9 | 1920 | | 968925 | 478328 | 490597 |
以下略
このような手順でオブジェクトストレージのデータをMySQLのテーブル(厳密にはHeatWaveのテーブル)に抽出し、分析を開始することができます。
しかし、同一テーブルに追加データを読み込ませたい場合は都度テーブルの削除と作成とロードが必要となるため、随時CSVファイルをアップロードすれば分析に使える…といった用途では使用することはできません。
また、使用するデータが1つであれば良いですが、複数ある場合都度CREATE文の作成が必要となり、非常に面倒な作業となります。
これを解消するためにオートパラレルモードと呼ばれている「CREATE文を自動生成してくれる機能」を試してみます。
半自動で読み込む(失敗/2023/12/08)
データを保存するデータベースを変数"@db_list"にセットします。
mysql> set @db_list = '["lakehouse_db"]';
Query OK, 0 rows affected (0.01 sec)
オブジェクトストレージに格納したcsvを読み込むための情報を変数"@ext_tables"にセットします。
mysql> SET @ext_tables = '[
{
"db_name": "lakehouse_db",
"tables": [
{
"table_name": "laketable",
"dialect": {
"format": "csv",
"field_delimiter": ",",
"record_delimiter": "\\n"
},
"file": [{
"prefix": "zenkoku/c01-zenkoku.csv",
"bucket": "bucket-lake",
"namespace": "【namespace名】",
"region": "ap-tokyo-1"}]
}
]
}
]';
Query OK, 0 rows affected (0.01 sec)
変数"@options"に上記設定を読み込むようセットします。
mysql> SET @options = JSON_OBJECT('external_tables', CAST(@ext_tables AS JSON));
Query OK, 0 rows affected (0.01 sec)
HeatWaveが用意しているロードのためのスクリプトを実行します。
mysql> CALL sys.heatwave_load(@db_list, @options);
+------------------------------------------+
| INITIALIZING HEATWAVE AUTO PARALLEL LOAD |
+------------------------------------------+
| Version: 2.20 |
| |
| Load Mode: normal |
| Load Policy: disable_unsupported_columns |
| Output Mode: normal |
| |
+------------------------------------------+
6 rows in set (0.02 sec)
+--------------------------------------------------------------------------------------------------------------------------------------+
| LAKEHOUSE AUTO SCHEMA INFERENCE
|
+--------------------------------------------------------------------------------------------------------------------------------------+
| Verifying external lakehouse tables: 1
|
|
|
| SCHEMA TABLE TABLE IS RAW NUM. OF ESTIMATED SUMMARY OF
|
| NAME NAME CREATED FILE SIZE COLUMNS ROW COUNT ISSUES
|
| ------ ----- -------- --------- ------- --------- ----------
|
| `lakehouse_db_3` `lakehouse` NO - - - Auto Schema Inference failed |
|
|
| New schemas to be created: 0
|
| External lakehouse tables to be created: 0
|
|
|
+--------------------------------------------------------------------------------------------------------------------------------------+
10 rows in set (2.12 sec)
+-----------------------------------------------------------------------------------------+
| OFFLOAD ANALYSIS |
+-----------------------------------------------------------------------------------------+
| Verifying input schemas: 1 |
| User excluded items: 0 |
| |
| SCHEMA OFFLOADABLE OFFLOADABLE SUMMARY OF |
| NAME TABLES COLUMNS ISSUES |
| ------ ----------- ----------- ---------- |
| `lakehouse_db_3` 0 0 1 table(s) are not loadable |
| |
| No offloadable schema found, HeatWave Auto Load terminating |
| |
+-----------------------------------------------------------------------------------------+
10 rows in set (2.13 sec)
すると、logを確認することで対象CSVを参照したCREATE文が出力されます。
そのはずでしたが、出力されません。。。;;
(公式ドキュメント通りにやっているはずなのに…)
出力されない原因は恐らく「Schema not present in input DB list」が発生しているためと思われますが、原因がわからず四苦八苦中です。。
本来はこのような形で出力されます。近日中に結果を修正しますのでしばしお待ちください。。。
下記は失敗しているため、Emptyな状態です。
SELECT log->>"$.sql" AS "Load Script" FROM sys.heatwave_autopilot_report WHERE type = "sql" ORDER BY id;
Empty set (0.01 sec)
まとめ
MDS Heatwave Lakehouse機能を紹介してみました。現時点では制限事項も多く若干扱いづらさを感じますが、今回紹介した制限事項は全て今後対応すると聞いているため、これらが解消されさえすればかなり良いサービスになるのでは?と思っています!
さらにオブジェクトストレージにアップロードしたCSVをそのまま分析できるようになってしまえば、向かうところ敵無し!なので、今後のアップデートに期待しています!