
皆さま、こんにちは!y.takanashiです。
本年1発目の記事となります🔥
2025年もよろしくお願いしますm(_ _)m
今回は OCI モニタリングサービス について、詳しく解説していきたいと思います。
目次
モニタリングとは?
OCI モニタリング(以下モニタリング)とは、Oracle Cloud Infrastructure(以下OCI)で提供されるリソース監視サービスです。
モニタリングを使用することで、システム管理者はOCI上のリソースの状態をリアルタイムで把握し、問題発生した際に迅速な対応が可能となります。
これにより、システムの性能や可用性を向上させることが期待できます。
モニタリングでは、主に以下の監視を安価に実施することができます。
- リソース監視
- 死活監視
- プロセス監視
- ログ監視
さらに、監視対象となるリソースはOCIのほぼ全てのサービスを網羅しています。

モニタリングの仕組み
モニタリングは、以下の仕組みで動作します。
- OCIで提供される標準イメージから作成したコンピュート・インスタンス(以下「コンピュート」)には、デフォルトで「 oracle-cloud-agent 」というモニタリング用エージェントがインストールされています。
- このエージェントは、数秒間隔でリソースの各メトリック(例:CPU使用率)をデータ・ポイント※として収集、サービス・ゲートウェイを通じてモニタリングに送信します。
これにより、モニタリング上でリソースの状態を確認できます。
データ・ポイント...タイム・スタンプ付きの単一の値。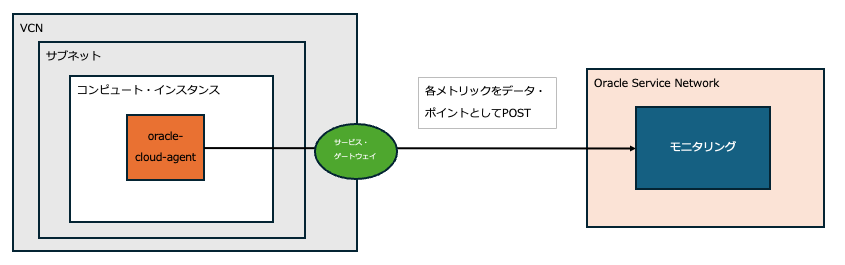
モニタリングを設定する前に、コンピュートの「Oracle Cloudエージェント」タブにある「コンピュート・インスタンスのモニタリング」を有効化する必要があります。
※デフォルトではこの設定が有効になっています。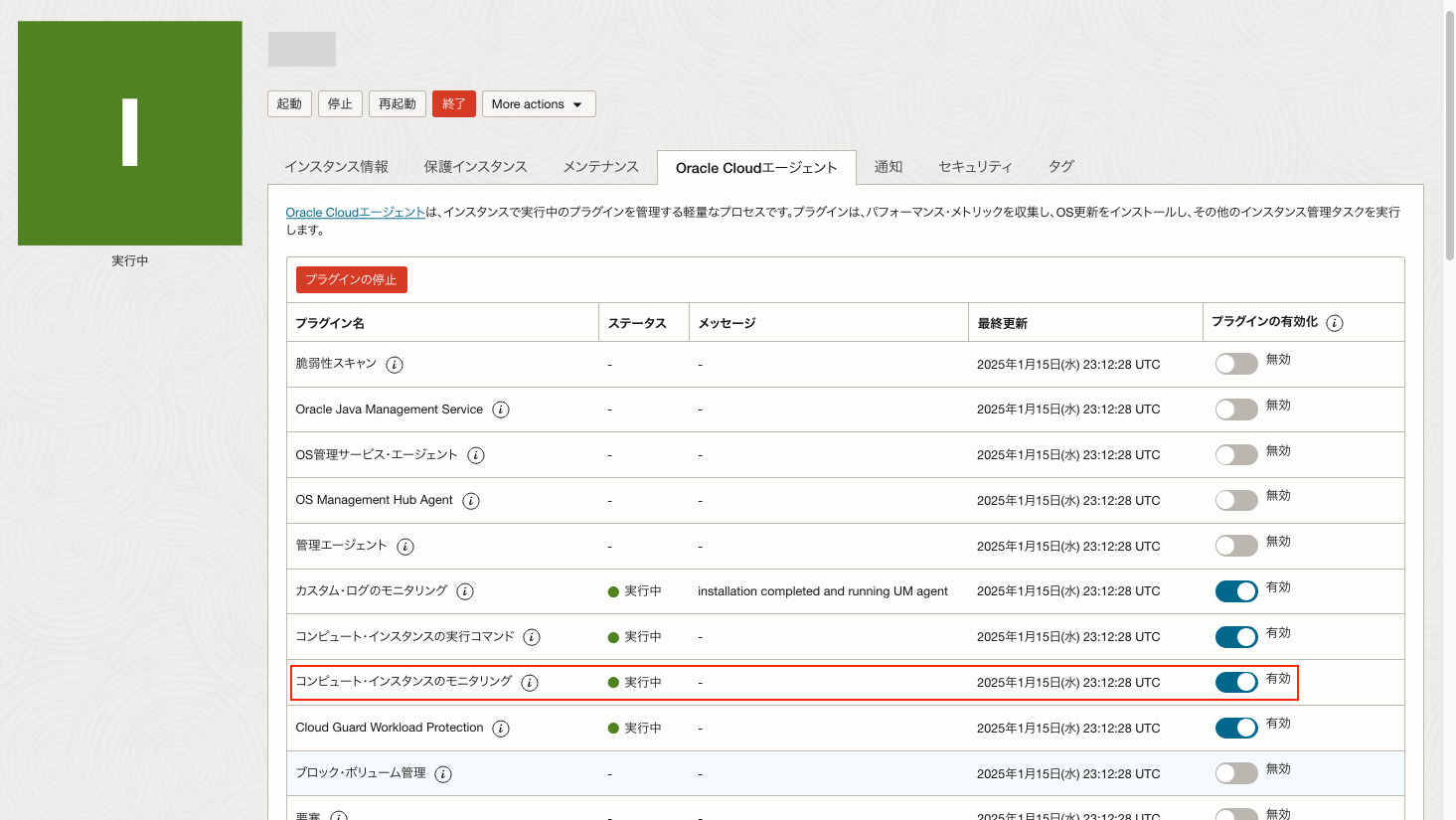
またカスタム・イメージを使用してコンピュートを作成した場合、oracle-cloud-agent がインストールされていないことがあります。
その場合、以下の対応が必要です。
- My Oracle Support に問い合わせて、対応するrpmパッケージを入手。
- 入手したパッケージを手動でインストール。
- インストール後、"systemctl status oracle-cloud-agent"を実行、"running"と表示されることを確認、表示された場合oracle-cloud-agentのインストールは完了となる。
また、モニタリングを利用する際は、セキュリティ・リストまたはNSG(ネットワーク・セキュリティ・グループ)に以下のセキュリティ・ルールを設定する必要があります。
- ステートレス:いいえ
- 方向:エグレス
- 宛先タイプ:サービス
- 宛先サービス:All NRT Services In Oracle Services Network
※東京リージョンの場合 - IPプロトコル:TCP
- ソース・ポート範囲:任意
- 宛先ポート範囲:443

事前準備
トピックの作成
モニタリングの解説に入る前に、アラームの通知先として使用する電子メールやSMSなどのエンドポイントを設定するために、OCIのトピックサービスが必要となります。
本解説ではトピックサービスの設定手順については範囲外のため割愛しますが、以下のドキュメントを参考に設定を進めてください。
※今回は、アラームの通知先として「電子メール」を使用します。IAMポリシーの設定
同様に使用ユーザーに管理者権限が付与されていない場合、IAMポリシー内に以下のステートメントを定義する必要があります。
Allow group <group_name> to manage alarms in tenancy
Allow group <group_name> to read metrics in tenancy
Allow group <group_name> to manage ons-topics in tenancy
Allow group <group_name> to use streams in tenancy構成要素
ここでは以下の監視要件を例に、モニタリングについて解説します。
- 対象サービス:コンピュート
- 対象メトリック:CPU使用率
- 監視間隔:5分
- 起動状態・重大度
- 80%・Error
- 90%・Critical
※5分間継続した場合に発報
モニタリングを作成する場合、OCIコンソール画面左上のナビゲーションメニューから「監視および管理」→モニタリング内の「アラーム定義」を選択します。
「アラームの作成(Create Alarm)」を選択します。
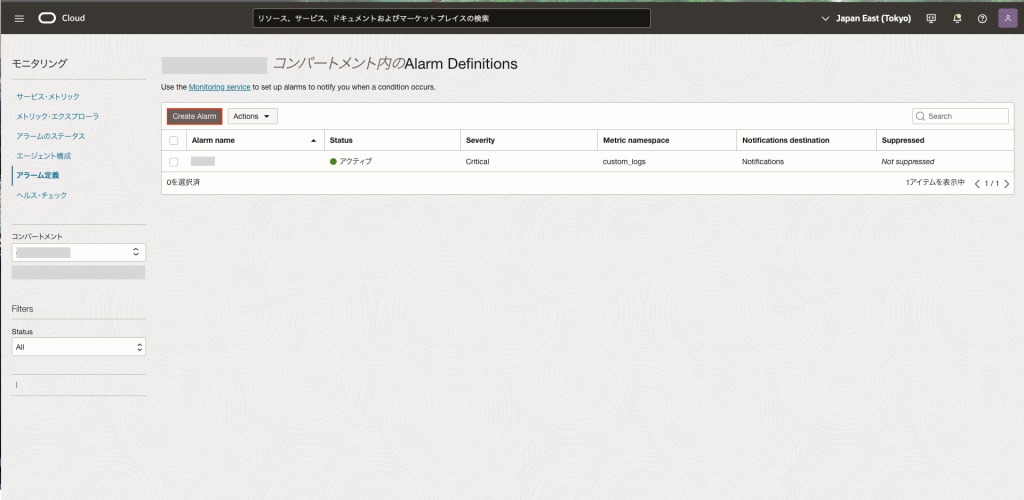
モニタリングは以下の構成要素から成り立ちます。
以降、各構成要素について解説していきます。
- アラーム定義(Define alarm)
- メトリック詳細(Metric description)
- メトリック・ディメンション(Metric dimensions)
- トリガー・ルール(Trigger rule)
- メッセージのグループ化(Message grouping)
- メッセージのフォーマット(Message format)
- 通知の繰り返し(Repeat notification)
- 通知の抑制(Suppress notications)
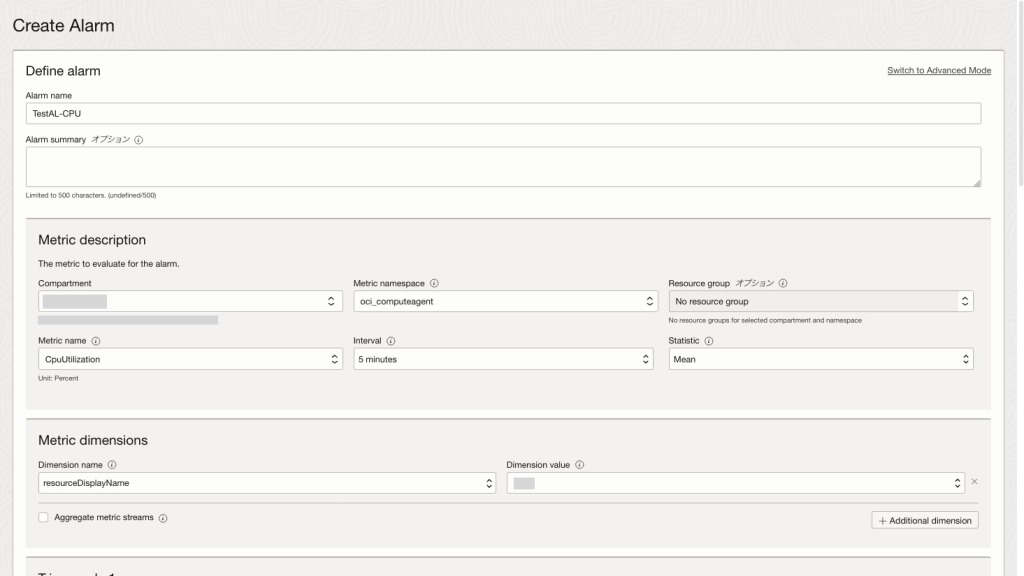
アラーム定義
アラーム定義は以下の要素で構成されます。
- アラーム名(Alarm name):アラームの識別名を設定します。
- アラーム・サマリー(Alarm Summary):アラームについて簡潔に説明する要約を、500文字以内で記載できます。オプション項目で空白で設定することも可能。
今回はアラーム名は「TestAL-CPU」で、アラーム・サマリーは空白のまま設定します。
アラーム名およびアラーム・サマリーは日本語で設定可能です。
調査や識別の容易さのため、日本語で設定することを推奨します。
また両要素とも「動的変数」というものを設定することも可能です。(詳細は「4.4.1 動的変数」で解説)
メトリック詳細
アラームに関連付けられるメトリック詳細は、以下の構成要素から成り立ちます。
- コンパートメント(Compartment)
- メトリック・ネームスペース(Metric Namespace)
- リソース・グループ(Resource Group)
- メトリック名(Metric Name)
- 間隔(Interval)
- 統計(Statistic)
コンパートメントはアラームを配置する対象のコンパートメントを指定します。
メトリック・ネームスペースは各メトリックを発行するリソースの名前空間を指定します。
コンピュートのCPUやメモリ、死活監視等基本的な監視は、デフォルトのメトリック・ネームスペース("oci_computeagent")で設定可能です。
ただし、ディスク使用率等はデフォルトのメトリック・ネームスペースには含まれていないため、以下のドキュメント等を参考に、ユーザー自身でカスタム・メトリックを作成する必要があります。(2025年2月時点)
※メトリック・ネームスペースは"oci_"もしくは"oracle_"が予約済み接頭辞として使用され、カスタム・メトリックを使用する場合はこれらを避ける必要があります。Oracle Cloud Infrastructureカスタム・メトリックを使用したディスク使用率の監視
リソース・グループはフィルタまたは結果の集計に使用カスタム文字列で、メトリックごとに適用できるリソース・グループは1つのみです。
カスタム・メトリックを使用せずデフォルトのメトリックを使用する場合、特に意識する必要ありません。
メトリック名は監視する具体的なメトリックを指定します。
間隔は、最小1分〜最大24時間まで選択可能です。
統計は指定された間隔でデータを集計する際の統計関数を選択します。
以下が主なオプションです。
| 演算子 | 意味 |
|---|---|
| Mean | 指定した期間の平均値 |
| Max | 指定した期間の最大値 |
| Min | 指定した期間の最小値 |
| Sum | 指定した期間の合計値 |
| Count | 指定した期間の観測数 |
| Rate | 間隔ごとの平均変更率(単位は秒) |
| P50,P90,P95,P99 | それぞれ50、90、95、99パーセンタイルの値 |
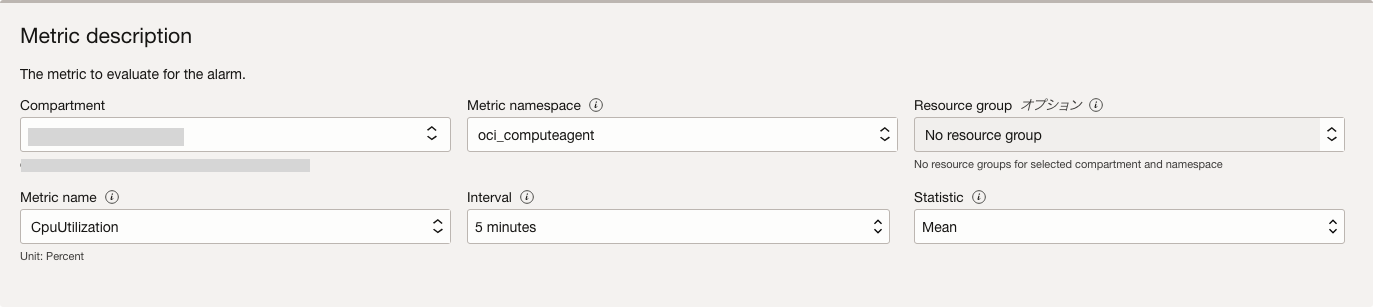
今回の要件に基づく設定例は以下の通りです。
- メトリック・ネームスペース:oci_computeagent
- リソース・グループ:デフォルト・メトリックを使用するため、指定なし
- メトリック名:CpuUtilization
- 間隔:5分(5 minutes)
- 統計:Mean
メトリック・ディメンション
メトリック・ディメンションはメトリックデータを分類、フィルタリング、およびグループ化するために使用される機能です。
名前(Dimension Name)と値(Dimension Value)のペアで構成され、特定のリソースやコンポーネントにフォーカスして監視を行うことが可能です。
以下は、今回の要件で利用可能なディメンション一覧です。
- AD(availabilityDomain)
- 専用仮想マシン・ホストOCID(dedicatedVMHostId)
- FD(faultDomain)
- イメージOCID(imageId)
- インスタンス・プールOCID(instancePoolId)
- リージョン(region)
- リソース名(resourceDisplayName)
- リソースOCID(resourceId)
- シェイプ(shape)
メトリック・ディメンションは1つのアラームにつき、最大2つまで作成可能です。
特定のリージョンや仮想マシン、リソースをグループ化して監視する際に役立ちます。
groupByの活用
groupByは、メトリック・ディメンションをグループ化してアラームを効率的に設定する際に使用します。
この機能を活用することで、以下のメリットがあります。
- 不要なアラームの回避:新しいディメンションがOCIに導入された際でも、無関係なアラーム・トリガーを防ぐことができます。
たとえば、最初は空のメトリック・ストリームが作成されることがありますが、GroupByを指定すると、それに基づく不要なアラーム発生を抑えられます。 - 特定のメトリック・ストリームの監視::GroupByを使用すると、アラームは指定されたディメンションでグループ化されたメトリック・ストリームのみを監視します。
指定しない場合の挙動: GroupByを指定しない場合、アラームはすべてのメトリック・ストリームを監視対象とします。
たとえば、CpuUtilization[1m].absent()という問合せでは、他のメトリック・ストリームの存在に関係なくアラームがトリガーされます。
groupByは基本モード(Basic Mode)では設定不可で、拡張モード(Advanced Mode)に変更、MQL※内に以下クエリの追加を行います。
※Monitoring Query Languageの略で、OCI のモニタリングで使用される問合せ言語で、メトリックデータの取得や分析に使用されます。groupBy(使用するディメンション)
メトリック・ストリームの集計(Aggregate metric streams)は、複数のメトリック・ストリームを1つにまとめて分析を行うために使用します。
これにより、例えば複数のコンピュートのCPU使用率を1つに統合して監視することが可能です。
今回の要件に基づくメトリック・ディメンションの具体的な設定は以下の通りです。
- ディメンション名:resourceDisplayName
- ディメンション値:監視するコンピュート名
- メトリック・ストリームの集計:無効

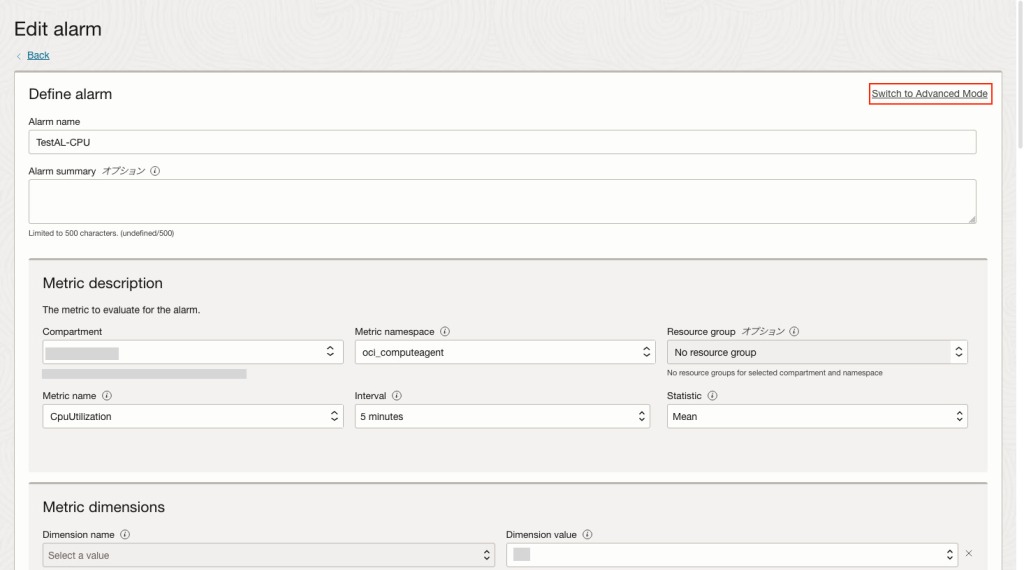
groupByを使用して設定する場合、「拡張モードにスイッチ(Switch to Advanced Mode)」を選択します。
拡張モードでは、「Query Code Editor」に直接クエリを記述して細かい設定を行うことが可能です。
以下はGroupByを使用した具体的な設定例です。
- CPU使用率を80%に設定する場合
- CpuUtilization[5m]{resourceDisplayName = "コンピュート名"}.groupBy(resourceDisplayName).mean() >= 80
- CPU使用率を90%に設定する場合
- CpuUtilization[5m]{resourceDisplayName = "コンピュート名"}.groupBy(resourceDisplayName).mean() >= 90
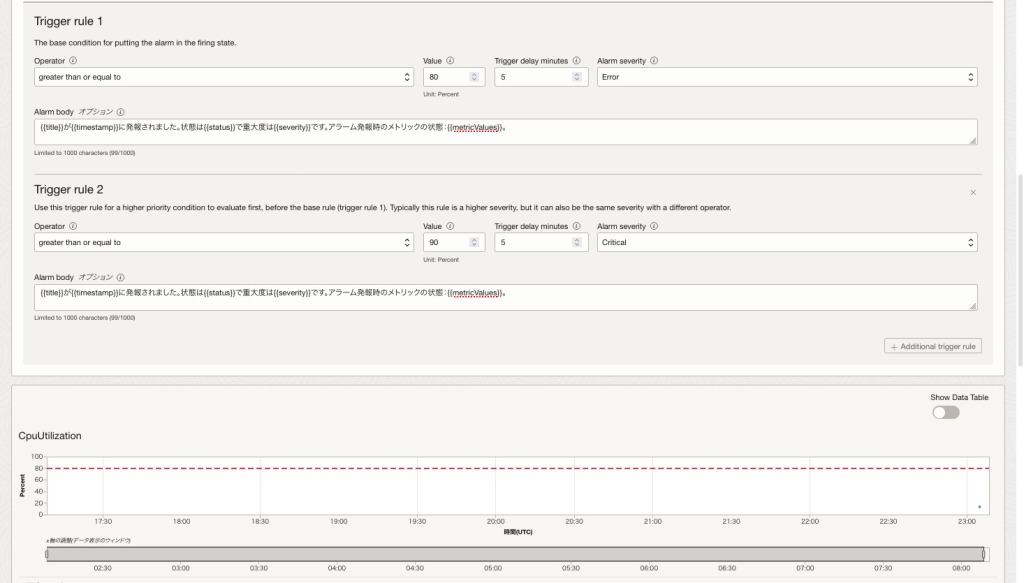
トリガー・ルール
トリガー・ルールとはアラームが起動状態にするために満たすべき条件を定義するものです。
トリガー・ルールは以下の要素から構成されます。
- 演算子(Operator)
- 値(Value)
- トリガー遅延分数(Trigger delay minutes)
- アラーム重大度(Alarm Severity)
- アラーム本体(Alarm Body)
演算子は条件を評価するために使用され、以下から構成されます。
- 〜より大きい(greater than)
- 〜より大きいか等しい(greater than or equal to)
- 〜と等しい(equal to)
- 〜より小さい(less than)
- 〜より小さいか等しい(less than or equal to)
- 〜までの範囲(between)
- 〜までの範囲外(outside)
- 不在(absent)
演算子の内の不在(absent)について、メトリックが指定した間隔全体で存在しない場合、1(true)を返します。
一方、間隔中にメトリックが存在した場合は、0(false)を返します。
この不在句を利用することで、死活監視用アラームを作成することが可能です。
値はアラームを発報する数値を入力します。
トリガー遅延分数は条件が連続して維持される必要がある時間を設定、「継続時間」として置き換えて考えることができます。
アラーム重大度は以下から選択可能です。
- Critical
- Error
- Warning
- Info
アラーム本体はアラームの詳細やメッセージ内容を記述します。
動的変数
アラーム本体は、アラーム名とアラーム・サマリー同様に、日本語で設定することが可能です。
設定時には「動的変数」を活用することで、発報時に対応するデータが自動的に置き換わり、より詳細な情報を含むアラーム・メールが送信されます。
注意点として、対応するデータがない場合、その変数は未解決になり、コード形式で表示されます。
以下が主な動的変数です。
| 動的変数 | 対応するパラメータ名 |
|---|---|
| {{title}} | アラーム名 |
| {{status}} | ステータス |
| {{timestamp}} | タイムスタンプ |
| {{severity}} | 重大度 |
| {{metricValues}} | メトリック・ディメンション |
他の使用可能な動的変数については、以下のドキュメントをご参照ください。
トリガー・ルールは1つのアラームにつき、最大2つまで作成可能です。
設定する際、以下の設定ルールが適用されます。
- 重大度の順序
- 重大度はルール2 > ルール1で設定可能
- ルール1 > ルール2は設定不可
- 異なる演算子の使用
- 同じ重大度で設定する場合、異なる演算子を使用可能
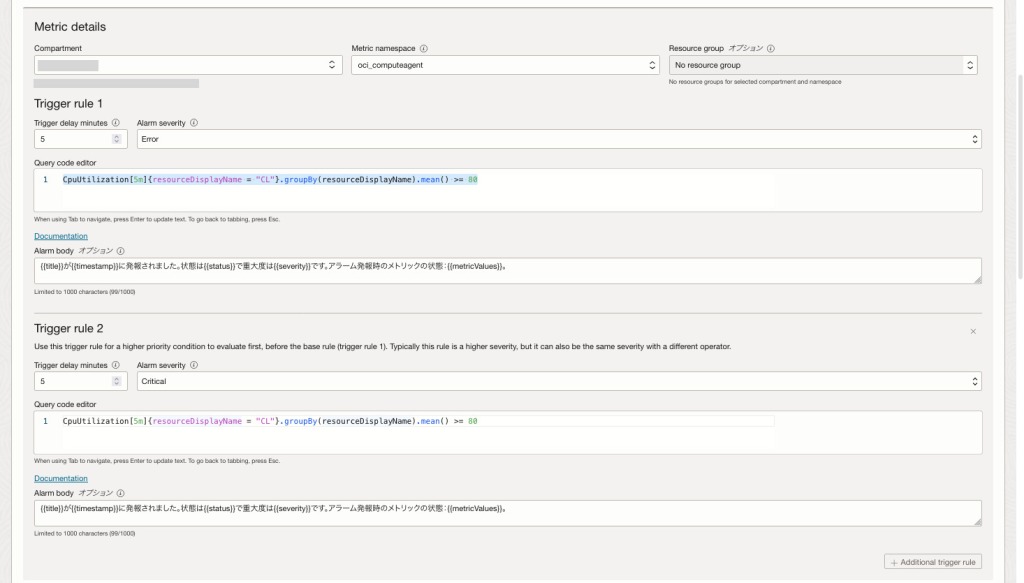
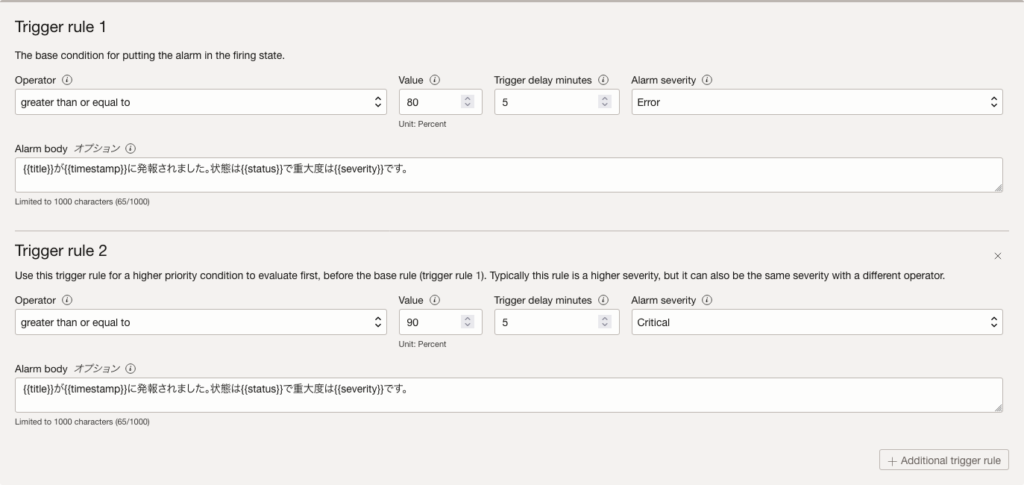
今回のケースでは、以下のように設定します。
- トリガー・ルール 1
- 演算子:〜より大きい(greater than or equal to)
- 値:80
- トリガー遅延分数:5分
- アラーム重大度:Error
- アラーム本体:{{title}}が{{timestamp}}に発報されました。状態は{{status}}で重大度は{{severity}}です。アラーム発報時のメトリックの状態:{{metricValues}}。
- トリガー・ルール 2
- 演算子:〜より大きい(greater than or equal to)
- 値:90
- トリガー遅延分数:5分
- アラーム重大度:Critical
- アラーム本体:{{title}}が{{timestamp}}に発報されました。状態は{{status}}で重大度は{{severity}}です。アラーム発報時のメトリックの状態:{{metricValues}}。
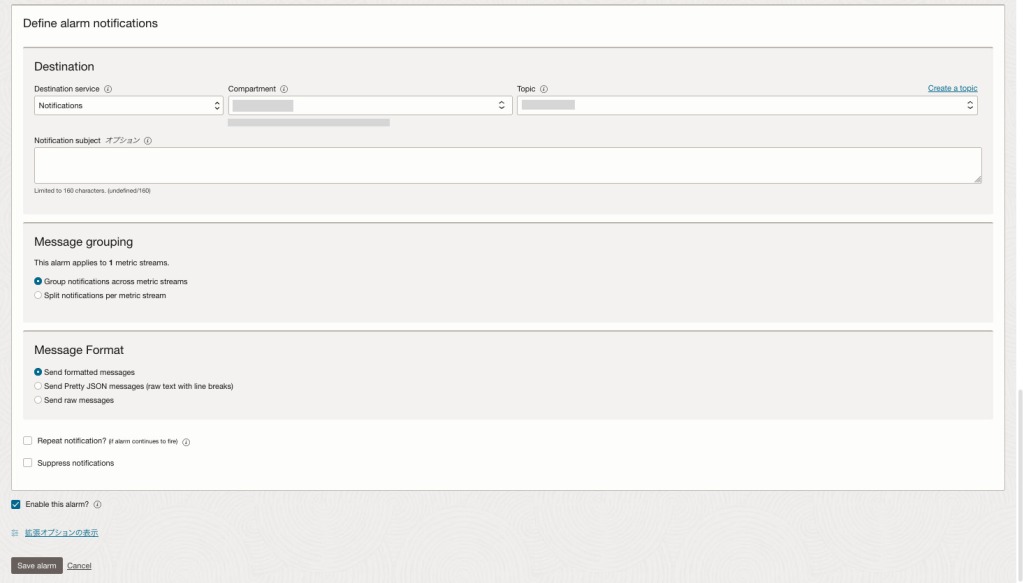
メッセージのグループ化
メッセージのグループ化について、以下の2つから選択可能です。
- メトリック・ストリーム全体で通知をグループ化(Group notifications across metric streams)
- すべてのメトリック値がディメンション別にまとめられ、メトリック・ストリームの順序でリストされ、単一のアラーム・メールが送信されます。
- メトリック・ストリームごとに通知を分割(Split notifications per metric streams)
- 単一のメトリック・ストリームに対応する単一のメトリック値を、ディメンション別にリストします。
- 結果として、単一のメトリック・ストリームごとに個別のアラーム・メールが送信されます。

メッセージのフォーマット
メッセージのフォーマットから、アラーム・メール受信時の形式を以下から選択することができます。
- フォーマットされたメッセージの送信(Send formatted messages)
- JSONメッセージでの送信(Send Pretty JSON messages)
- 生ログでの送信(Send raw messages)

通知の繰り返し・通知の抑制
通知の繰り返し(Repeat notification)は、有効化することにより、アラームが起動状態の間に指定した間隔でアラートを繰り返し通知を送信します。

通知の抑制(Suppress notifications)は指定した期間中、アラームを非アクティブ状態にすることができます。
モニタリング用アラームを作成すると、ステータスは「Ok」となります。
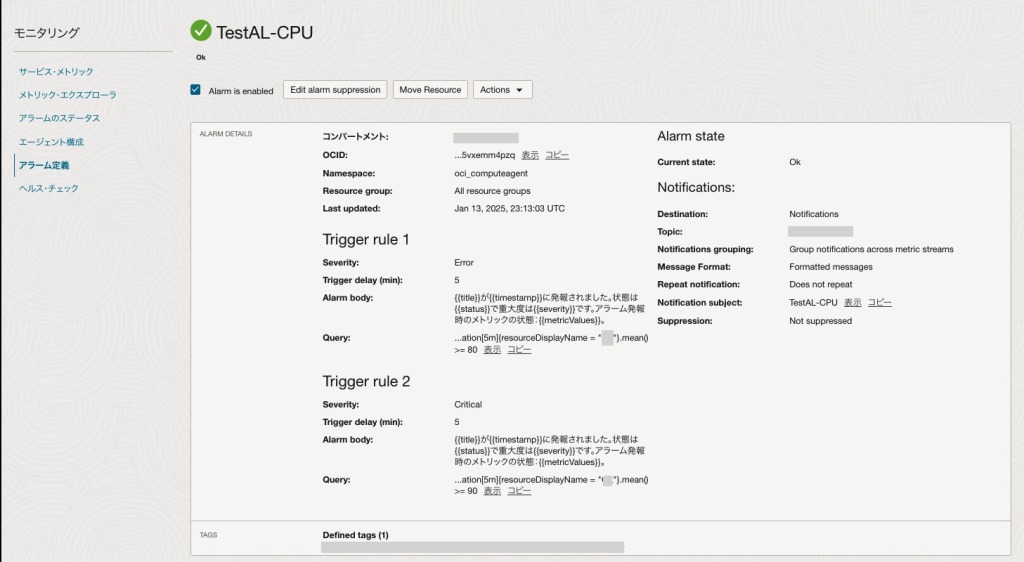
モニタリングの構成要素の解説については以上です。
アラーム・メール
全ての設定が完了したら、stressコマンドを使用してCPU使用率を意図的に高め、アラーム・メールの送信内容を確認します。
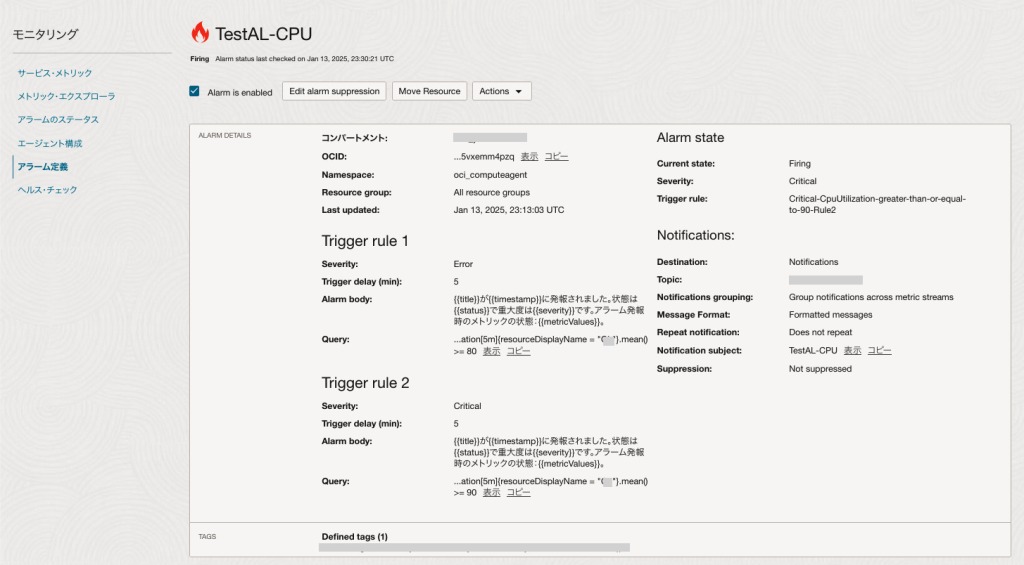
アラームが発報した場合、Oracleから以下の内容でメールが送信されます。

またOCIコンソール画面でアラームの状態を確認すると、ステータスは「Firing」の状態となります。
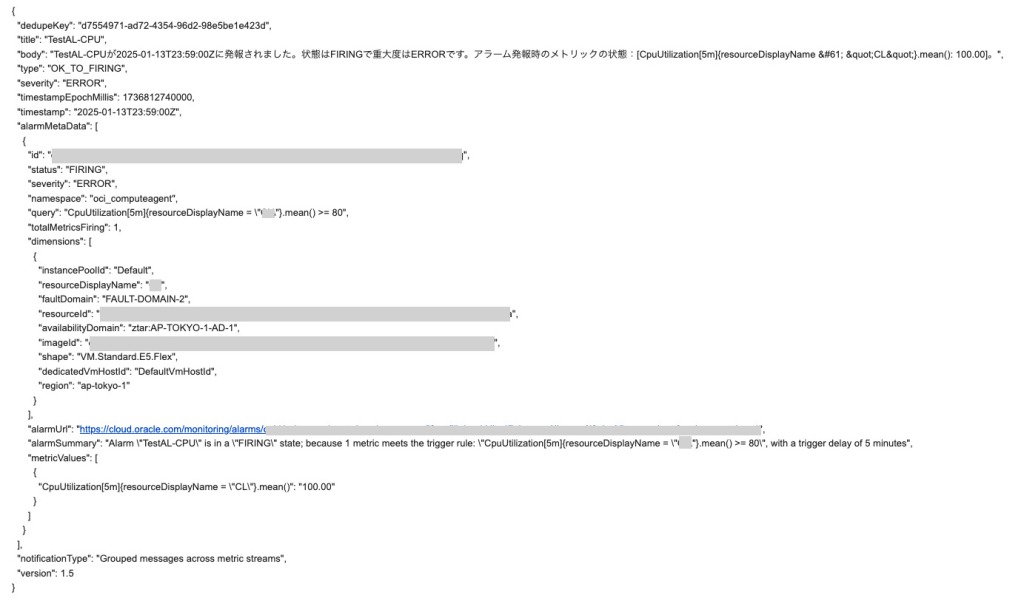
アラームが解除されると、Oracleから以下の内容のメールが届きます。
「動的変数」で説明したように、変数が参照できない場合、未解決となりコード化された状態で表示される点に注意してください。

OCIコンソール画面では、 ステータスは「Ok」に戻ります。
ちなみに、「メッセージのフォーマット」でJSON、RAWログをそれぞれ選択した場合、以下の形式でメールが送信されます。

料金体系
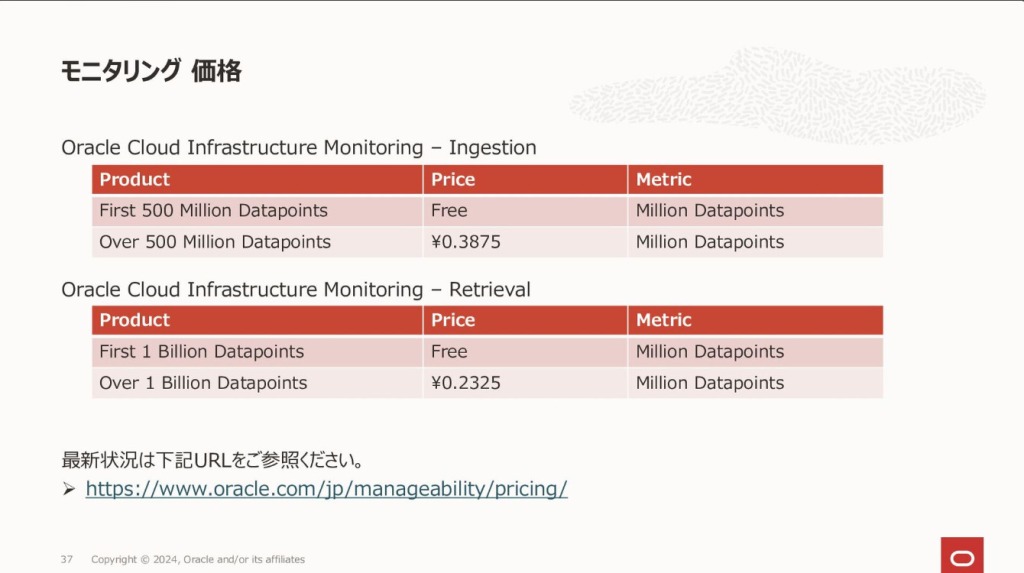
モニタリングはIngestion(データの取り込み)とRetrieval(データの取得)に応じて料金が発生します。
Ingestionはカスタム・メトリックのデータポイントがモニタリングに送信された際に料金が発生します。
一方、OCIの各サービスに含まれるデフォルトのメトリックについては料金は発生しません。
今回はデフォルトのメトリックを使用しているため、Ingestionに関する料金は発生しません。
Retrievalの料金は以下のような操作や使用に基づいて課金されます。
- コンソールでのグラフ表示およびリロード
- メトリックを可視化するためのグラフを表示した回数やリロードした回数。
- サービス・コネクタ・ハブを介したデータ移動
- モニタリングのデータポイントが他のサービスに移動された際のデータ量に応じた課金。
価格については以下となっております。(2025年2月現在)
まとめ
モニタリングは、OCIで提供されるリソース監視サービスで、主に以下の監視を安価に実施できます。
- リソース監視
- 死活監視
- プロセス監視
- ログ監視
モニタリングは、以下のように動作します。
- OCIで提供される標準イメージから作成したコンピュート・インスタンス(以下「コンピュート」)には、デフォルトで 「oracle-cloud-agent 」というモニタリング用エージェントがインストールされています。
- このエージェントは、数秒間隔でリソースの各メトリック(例:CPU使用率)をデータ・ポイントとして収集、サービス・ゲートウェイを通じてモニタリングに送信します。
- これにより、モニタリング上でリソースの状態を確認できます。
モニタリングは以下の構成要素から成り立ちます。
- アラーム定義(Define alarm)
- メトリック詳細(Metric description)
- メトリック・ディメンション(Metric dimensions)
- トリガー・ルール(Trigger rule)
- メッセージのグループ化(Message grouping)
- メッセージのフォーマット(Message format)
- 通知の繰り返し(Repeat notification)
- 通知の抑制(Suppress notications)
モニタリングは以下に応じて料金が発生します。
- Ingestion(データの取り込み)
- カスタム・メトリックのデータポイントがモニタリングに送信された際に料金が発生
- OCIの各サービスに含まれるデフォルトのメトリックについては料金は発生しない
- Retrieval(データの取得)
- メトリックを可視化するためのグラフを表示した回数やリロードした際に発生
- モニタリングのデータポイントが他のサービスに移動された際のデータ量にも課金される
以上となります。
この記事を通じて読者の皆様の問題解決の一助となれば幸いです。
最後まで読んで頂き、ありがとうございましたm(_ _)m