
はじめに
こんにちは!記事を書くのが何年ぶりなのか不明の k.furusawa です! 今回、AIを活用してAIチャットボットを作成したので、その備忘録とAIを活用した開発の所感等々を書き残しておこうかと思います!
ちなみにこの記事にAIは用いられていません。人の温かみを感じる100%ヒューマン製です!
本記事の対象者
- ある程度の開発経験がある人
- 開発用語の解説は行いません
- AIを利用した開発のざっくり所感を知りたい人
- 細かなプロンプト内容等の紹介は行いません
- コードを用いた細かな開発内容の説明も行いません
止まることを知らないAIの流れ
前に記事を書いた時(おそらく2020年)から世の中が大きく変わりました。私もいつの間にか在宅ワークがメインとなり、生活がかなり変わりました。
ここ最近の大きな変化といえば、やはり話題のAIですね!イラスト、音楽といった芸術分野から、医学、農業、その他諸々、ありとあらゆる場所にAIが登場してきています。その流れは今やIT分野、特に開発の世界にも流れ込んできています。この流れが止まることはそうそうないと思います。
社内開発におけるAIに対する取り組み
弊社の開発部でも積極的にAIを活用していこう!なるべく経験値を積んで共有していこう!という流れでおります。
社内セミナーが開かれたり、有償サービスに登録したり、AIエージェント専用のエディターを導入したりと積極的に取り組んでおります。 私も開発作業でAIを大いに活用しており、あるとなしでは作業が全く違います!
AIを活用してAIチャットボットを作ろう!
そんなAIですが、使うだけではなくAIを活用したものを開発しようとするといったいどんな知見が必要になるのでしょうか?
わかりません!
何せ今までと全く畑違いな分野です。何一つわからない。わからないなら作ってみるのが一番ですね。
そんなわけで!
今回は社内開発で行ったAI開発について記事にしていこうかと思います!前振りが長い!
作った「AIチャットボット」について
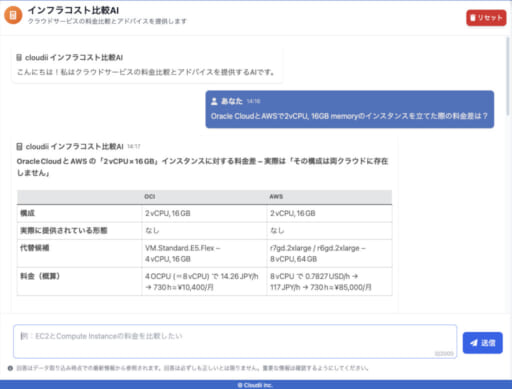
社内開発の一環で、「クラウド料金比較AIチャットボット」を作成しました。
何をするものかといえば、その名前の通り、クラウド料金の比較を行ってくれるボットの提供です。
- Oracle CloudとAWSで2vCPU, 16GB memoryのインスタンスを立てた際の料金差は?
- Oracle CloudのFLBとAWSのALBの違いは?
などなど、料金の比較だけではなくインフラ的な質問にもある程度答えてくれるチャットボットです。
開発の方針
今回はAIをとにかく活用しながら1つのサービスを作り上げる!という目的がありましたので、以下のような方針を決めました。
- フロントエンドは90%ほどAI生成
- バックエンドは基本設計と構成を人間が行い、ざっくりとした実装はAI生成
結果は後の苦労話で書きます!
利用したもの
今回の開発で利用したものは以下です。基本的にOracle Cloudで揃えました。
- オブジェクトストレージ(RAGファイルの格納)
- ADB(Autonomous AI Database)
- インスタンス1つ(アプリケーション、バッチ両用)
- 外部LLM
外部LLMはOpenAIとかGPTとか色々選択筋がありますが、今回は開発に助言をくれたメンバーの「超おすすめ!」という言葉を100%鵜呑みにして「Groq」を選びました。
- Groqとは?
Grokじゃないですよ!
公式HPはこちら
GroqはAI専用のプロセッサを独自でもち、応答が爆速な上に精度がかなり良く、そして低価格!という至れり尽くせりのAIプラットフォームです。APIにももちろん対応しています。 今後値上げなども考えられますが、今のところは最適解の一つかと思います! 気になるポリシーでも学習内容は保存せずに外部に漏れることはない、とあるので問題なさそうです!
アプリケーション部分の開発はDjangoを選択しました。バックエンドとフロントエンドを別々のプロジェクトとして作成して管理するリソースがなかったので(実質開発者は私1名)、両方が手軽に揃えられるDjangoは最適解でした。 言語もPythonなのでAIとの相性もバッチリです。
エディタの話
AI生成をフルに活かすということで、エディタもAI対応かつそれに特化したものがいいということで、Cursorを利用しました。
- Cursorとは?
Cursorの公式HPはこちら
CursorはAI生成開発に特化したVisualStudioCodeのフォークプロジェクトです。エージェントにClaudeを選択できるのがありがたいです! Claudeは出力精度がかなり高いですし、Pythonとの相性も良いです。
Cursorの特徴としてAIによるコード補完がかなり強力で便利です。正直これを経験しちゃうとただのCodeに戻れなくなります。難点として、Cursorは高いです。AIエージェントは月に利用できるLimitが小さいのでガッツリ使うと課金地獄になります。何がしたいのか、どんな結果を望むのかを事前に固めておいて、なるべくやりとりを少なくする工夫をした方がいいです。
VisualStudioCodeはどうなの?
最近はVisualStudioCodeでもAIエージェントが利用できますので試したのですが、Codeはいい結果は出せませんでした。
GPT4を使っているはずですがコードの認識精度がかなり低く、指示の解釈精度も低すぎてほとんど使い物になりませんでした。入力・出力するリソースが多くなると露骨に精度が下がるので、コードの生成にはまだ不向きな印象です。ライブラリのメソッド検索や構文チェックくらいなら使えると思います。
AIチャットボットを開発していく
どんな仕組みか?
今回のAIチャットボットの仕組みはシンプルです。というかこれくらいしか知りません。世の中にはもっと複雑なものもあると思いますが、AI開発のスタートラインということで。
- ADBにRAGファイルを元にしたベクトル情報を格納する
- ユーザー質問をベクトル変換し、ADBに対して距離検索をかける
- 得られた結果を元にLLMに回答の作成を行わせる
ざっくりといえば上記のようになります。 もうちょっと詳しいフローを書きます。
ADBにデータを入れるまでのフロー
- Oracle CloudのオブジェクトストレージからRAGファイルを取得
- ファイル内容をデータ単位で分割
- 2のデータを自然文になるように変換
- 3の内容をベクトル変換
- 4の内容をADBへ格納する
3が少し曲者です。
今回はユーザーからの質問を受ける形なので、どんな質問が来るか不明です。そしてそれは100%自然文でjson形式などデータではありません。
なのでADBに対する検索精度を向上させるには、RAGファイルの内容(今回は料金情報をまとめたjsonファイル)をそのままベクトル化しても精度向上にはつながりません。
jsonの内容をデータごとに切り分けて、そこから自然文を作成し、ベクトル化します。
例)
{
"display_name": "Oracle Cloud VMware Solution - BM.DenseIO.E4.64 - 1 year Commit",
"service_category_display_name": "Compute - VMware",
"price_type": "HOUR",
"price_value": 10,
"price_model": "PAY_AS_YOU_GO",
"currency_code": "JPY"
}↓
Oracle Cloudの BM.DenseIO.E4.64 VMウェアソリューションの料金情報
料金体系は従量課金
単位は1時間ごとに10 JPY
みたいな感じです。情報は多ければ多いほどいいですし、英語と日本語両方あるとなお良いです!
質問の送信と回答までのフロー
フロントエンド
- フロントアプリケーション(チャット画面)
- ユーザーの質問をバックエンドに送信
バックエンド
- 受け取った質問内容をLLMに解析させて最適化
- 最適化した質問をベクトル化
- ADBに対してコサイン距離検索
- 得られた結果をプロンプト、会話履歴とともにLLMに引き渡せるよう加工
- LLMに解析と回答の作成を依頼
- LLMからの回答をストリーミングで取得しつつフロントに戻す
- DBに回答履歴を保持
フロントとバックの仕組みは特別なところはないです。
1つ注意点があるとすれば、ベクトル化する際はADBに格納する際に用いたベクトル化と同じ方法を行う必要があります。 なんでかといえば、ベクトル化の方法は様々ありやり方によってデータ長が変わります。
違う変換をしたベクトルで検索するとADBに怒られるか、何も返ってきません。
ベクトル化で用いたモデル
ベクトル化する際にはインスタンス内でCPU変換してます。本当はGPUでやるのが理想ですが、お値段が・・・。
モデルは paraphrase-multilingual-MiniLM-L12-v2 というのを用いました。日本語にも対応してます。Miniとあるようにモデルサイズも省スペースです(それでも2GBある)。
Oracle CloudのGenerative AI Agentは使わないの?
元々はOracle CloudのGenerative AI Agentを用いてRAGファイルの解析とLLM回答を一括してできるようにする予定だったのですが、 AI Agentの回答の精度があまり良くなかったのと、RAGファイルの状態を監視できない、レスポンスが遅い、などなどチャットボットとして提供するには課題が多かったので見送りました。(1番の原因は管理画面とAPIにバグが多すぎる点です)
作成したチャットボットは後日公開予定
今回開発したチャットボットですが、後日公開予定です。 どなたでも利用できるようにする予定ですので、公開されましたら触っていただけたら幸いです。
苦労話
順調に開発できたように思われそうですが、実際は以下のような苦労がありました。
- 先駆者の少なさ(情報があまりない)
- AIが悪いのか、実装が悪いのかの切り分けが難しい
- RAGファイルの分割方法と自然文作成に至るまでが長かった
- 専門用語を認識させるのが難しい
先駆者の少なさ
AI開発はまだまだこれからの分野なので、先駆者がそう多くありません。 調べれば情報は出てきますが、今までの開発と分野が違いすぎてどの情報がどこまで信頼できるのかの精査も難しかったです。
とりあえず取り入れてみて、効果があるか?ないか?のような地味な調査が多かったです。
AIが悪いのか、実装が悪いのかの切り分けが難しい
ADBにデータを入れて、検索してみて、AIに回答させたが結果が悪くて・・・となった時に調査するのですが、これが割と苦労しました。
どこのフェーズで精度が落ちたのか?というのが簡単に切り分けできないからです。 AIに渡したプロンプトか?ベクトル内容か?その元になった自然文?さらにその元ネタのjsonデータ? データ元が悪かったり、ADBの検索に問題がある場合はまだいいです。AIに渡した段階になるとプロンプトの調節など、また違ったスキルが必要になります。
RAGファイルの分割方法と自然文作成に至るまでが長かった
開発中盤になかなか精度が上がらなくて困りました。その時は料金のjson内容をそのままベクトル化していたのですが、検索スコアが0.4あたりをウロウロ・・・。
困り果てて結果的にAI関連のことはAIに聞け!ということでGeminiとGPTに同じ料金情報を渡して、「この情報からデータ検索するとして、どのようなデータがあれば正確な情報を出せるか?」といったことを聞きまくるということをしました。
結果「jsonは同じ構成の文が続くため自然文のベクトル検索に適さない」という結果を多数得たので、自然文への変換を取り入れることになりました。
専門用語を認識させるのが難しい
今回はクラウド料金の比較だったので、当然ながらクラウドサービスについてある程度認識できる状態にしないといけません。
しかし、ALBやらFLBやらOCPUやらvCPUやら、クラウド固有の名称をLLMが学習済みかといえばその限りではありません。名前も似ているので誤認も頻繁にします。
なので、今回はプロンプトになんの略称であるのか、どういった仕様であるのか、といった情報を持たせました。しかしプロンプトの長さにも限界がありますので、その調節具合に随分と苦労しました。
AI生成を活用した開発の雑感
先にも書いたように、今回はAI生成を用いて以下のような方針で開発を行っています。
- フロントエンドは90%ほどAI生成
- バックエンドは基本設計と構成を人間が行い、ざっくりとした実装はAI生成
AI生成する際に、プロンプトの整備とAIに読み込ませる基本設計書を用意しました。
- プロンプトをまとめたファイル(マークダウン推奨)
- どういったアプリを必要としているか、どういった機能を提供するかなど基本的な情報
- どんな画面か、といった説明とスクリーンショット
- テーブル構成(ざっくり)
- プロジェクトのフォルダ構成(なるべくMVCに沿った理想的な形にする)
- 認証はどうするか、などなど
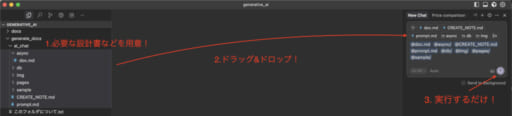
これらを用意したら、Djangoの空のプロジェクトを作成して、エディタ(今回はCursor)で開きます。
そしてエディタのAIをエディットモードにして、上記のものをドラッグ&ドロップで渡し、生成開始するだけです!(この時、プロンプトをメッセージ欄に追加するとさらに精度が上がります)
あとは勝手に空のプロジェクト内に必要なものをドンドン作成してくれます!見てて面白いですよ。
結果どうだったか
フロントエンドは驚くほど正確に出力してくれました!
驚きなのはスクリーンショットそっくりな画面を初回で出力してくれたことですね。フロント開発はもうお仕事なくなるかも、、、と本気で心配になりました。
ただ、AIは目が見えているわけではないので、細かな調節は人間の手がやはり必要です。特に色周りはやたらとカラフルだったり、白背景に白文字を出力したりと苦手そうでした。
| 入力したスクリーンショット | 出力された画面 |
|---|---|
 |
 |
↑出力された画面は、ほぼ人間の手を入れてません。謎にグラデーションが入っていたりツッコミどころはありますが、その後もこれをベースに多少直す程度で開発が進みました。
バックエンドはまだ厳しい点が多い
課題が多かったのはバックエンドで、確かに動くレベルなのですがコードがかなり散らかり、MTV(あるいはMVC)のルールに基づかなかったり指示していない無意味なモデルが生まれたりとなかなか思うものは出力してくれませんでした。
3回ほど試したのですが、結局一番効果的だったのが機能ごとのサンプルコードをとりあえず私が作って、それを一つ一つ読ませて作らせる方法でした。いきなりドカンと作らせるにはバックエンドは複雑で多機能なのでよほど精緻なプロンプトと設計書が必要になるようです(そこまで行くともう自分で作りたくなりますが)。
AI生成を活用した開発は課題も多いが使い方次第
コードのAI生成は利用モデルによって大きな差が出ますが、今のところ共通する課題として以下があるかなと思いました。
- 指示内容に含んでいないことを進めて余計なことをする
- 人間以上に「やっていいこと」と「やってはいけないこと」を明確にしないといけない
- コーディングルールの教え込みに穴があると穴通りの間違いをしがち
要するにプロンプトと設計書を詳細に用意しろということなのですが、人間相手なら割とその辺りの意思疎通や認識合わせがアバウトにできてしまったりします。
逆に言えば、そういったものが最初から準備できているプロジェクトにおいては強力に働いてくれると思います。 また、エディタの項でも書いたようにAIによるコード補完やコーディングチェックがかなり便利なので、コード全体のAI生成で威力が出せなくても、作業者のアシスタントとして現時点でも作業速度を上げる役には十二分に立っていると思います。
最後に
まだまだ発展途上なAI開発ですが、今後も広がりを見せるのは確実です。
完全にAIに任せきりにするには先述したように課題が多いですが、今のところは便利に使わせていただいています。 勿論、社外の開発に関わる際はAIの利用がOKなのかなど色々と確認が必要ではありますが、今後の開発ではメジャーあるいは必須となる革新的なものであるのは間違いない、と感じています。精度もどんどんと上がっているので、正直今回の開発程度で追いつけたとは思えませんが、その入り口に触れられたという点ではいい経験だったと思います。
実はOracle CloudのAIエージェントが提供しているモデルを用いた版も開発していたのですが、長くなるのであえて今回は言及しませんでした。 また書くことができたらお会いしましょう。