
皆様、こんにちは。h.serizawaです。
Oracle Cloud Infrastructure(OCI)では、Prometheus Node Exporterを使ってシステムメトリクスを収集し、OCIモニタリングで監視することができます。この記事では、メトリクスをOCIモニタリングに送信する2つの方式を、実際の構築手順とともに紹介します。
目次
- 1 🤔 なぜPrometheus Node Exporterを使ってメトリクスを収集するのか?
- 2 【第1部】管理エージェント方式の構築
- 3 【第2部】Loggingエージェント方式への移行
🤔 なぜPrometheus Node Exporterを使ってメトリクスを収集するのか?
OCIを使っていると、こんなことを思ったことがあると思います。
「あれ?ディスク使用量が見えない...」
「メモリの詳細な使用状況を知りたいのに...」
「ファイルシステムごとの空き容量を監視したい!」
OCIモニタリングの標準メトリックだけでは不十分
OCIモニタリングの標準メトリックだけでは、以下のような重要な情報が取得できません
- ❌ ディスク使用量(個別ディスクの状態)
- ❌ ファイルシステムごとの使用量(/、/home、/varなど)
- ❌ 詳細なメモリ使用量(active、buffer、cacheなど)
- ❌ プロセス数、ファイルディスクリプタ数
- ❌ ネットワークインターフェースごとの詳細統計
解決方法:カスタムスクリプト
これまでだと、以下のようなカスタムスクリプトを書いてメトリックを収集していました。
#!/bin/bash
# ディスク使用量を取得してOCIモニタリングにPUSH
DISK_USAGE=$(df -h / | awk 'NR==2{print $5}' | sed 's/%//')
# OCI CLIでメトリクスを送信
oci monitoring metric-data post \
--namespace "custom_metrics" \
--metric-data "[{
\"namespace\": \"custom_metrics\",
\"name\": \"disk_usage\",
\"dimensions\": {\"host\": \"$(hostname)\"},
\"datapoints\": [{
\"timestamp\": \"$(date -u +%Y-%m-%dT%H:%M:%S.000Z)\",
\"value\": $DISK_USAGE
}]
}]"
このスクリプトをcronで定期実行...
この方法のデメリット
- 📝 案件ごとに毎回スクリプトを書く手間 - 似たようなスクリプトを何度も作成
- 🔧 スクリプトの保守・メンテナンスが必要 - バージョンアップ、バグ修正
- 🐛 エラーハンドリングの実装 - ネットワークエラー、権限エラーなど
- ⏰ 開発に時間がかかる - 設計、実装、テスト
- 💰 運用コスト - 各インスタンスにデプロイ、監視、トラブルシューティング
お客様からの要望と制約
スクリプトを回すことで、以下のような要望や制約に直面します
🏢 セキュリティポリシー
「SaaS型の商用監視ソフトウェア(Datadog、New Relic等)の導入は禁止されています」💼 シンプルな運用
「OCIの標準機能だけで完結させたい。追加ツールの導入は避けたい」📊 一元管理
「OCIコンソールだけで全てのメトリクスを見たい」
しかし、OCIモニタリングの標準機能だけでは機能が足りない...
✨ Prometheus Node Exporter
そこで、今回のPrometheus Node ExporterとOCIエージェントを連携する仕組みを紹介します。
仕組み
- Node Exporter(Prometheusツール): システムメトリクスを収集・公開
- OCIエージェント(管理エージェント or Loggingエージェント): メトリクスをOCIモニタリングに転送
- OCIモニタリング: メトリクスを保存・可視化
この方式のメリット
| 項目 | カスタムスクリプト | Node Exporter + OCIエージェント |
|---|---|---|
| メトリクス収集 | スクリプトを毎回作成 | Node Exporterで自動収集 |
| メトリクスの種類 | 自分で選んで実装 | 600種類以上が標準で利用可能 |
| 開発工数 | 毎回 数時間〜数日 | 設定だけで完了(10分) |
| 保守 | スクリプトのメンテナンス必要 | メンテナンスフリー |
| OCI統合 | 別途実装が必要 | OCIモニタリングに自動統合 |
| セキュリティ | スクリプトの品質に依存 | OCI標準サービス |
取得できる主要メトリクス例
- 💾 ディスク: 使用量、I/O統計、読み書き速度
- 🗂️ ファイルシステム: マウントポイントごとの空き容量
- 🧠 メモリ: active、inactive、buffer、cache、swap
- ⚙️ CPU: コアごとの使用率、モード別時間
- 🌐 ネットワーク: インターフェースごとの送受信バイト数、エラー数
- 📊 システム: ロードアベレージ、プロセス数、起動時間
誰にとってメリットがあるか
エンジニアにとって:
- ⏱️ スクリプト開発時間の削減(数時間〜数日 → 10分)
- 🔧 保守負担の軽減(メンテナンスフリー)
- 📈 案件での標準化(毎回同じ方法を使える)
お客様にとって:
- 🔒 セキュリティポリシーに準拠(商用監視ツールのライセンス不要)
- 💰 コスト削減(SaaS型監視サービスの月額費用不要)
- 🎯 シンプルな運用(OCIコンソールだけで完結)
会社にとって:
- 💼 提案力の向上(「OCIだけで完結できます」と言える)
- 🚀 案件対応のスピードアップ(即座に導入可能)
この記事で学べること
この記事では、Prometheus Node Exporterで収集したメトリクスをOCIモニタリングに送信する2つの方式を実際に構築していきます。
- 管理エージェント方式
- Loggingエージェント方式
🎯 概要:2つの方式の違い
Prometheus Node Exporterで収集したメトリクスをOCIモニタリングに送信する方式は、大きく2つあります。
管理エージェント方式
SSHでインスタンスにログインし、.propertiesファイルを手動で作成・配置する方式です。
- ✓ 成熟した技術で安定している
- ✗ 手動作業が多い
- ✗ 複数インスタンスへの展開が大変
Loggingエージェント方式
OCIコンソールから「エージェント構成」を作成するだけで、設定ファイルが自動生成される方式です。
- ✓ 設定ファイルの手動作成が不要
- ✓ 動的グループで複数インスタンスに一括適用
- ✓ OCIコンソールから一元管理
📋 前提条件
- OCIのコンパートメントが作成済み
- VCNとサブネットが作成済み
- インスタンスが起動済み(Oracle Linux 9)
- インターネット接続可能
- SSHキーでインスタンスにログイン可能
インスタンスの作成
OCIコンソールでインスタンスを作成します。
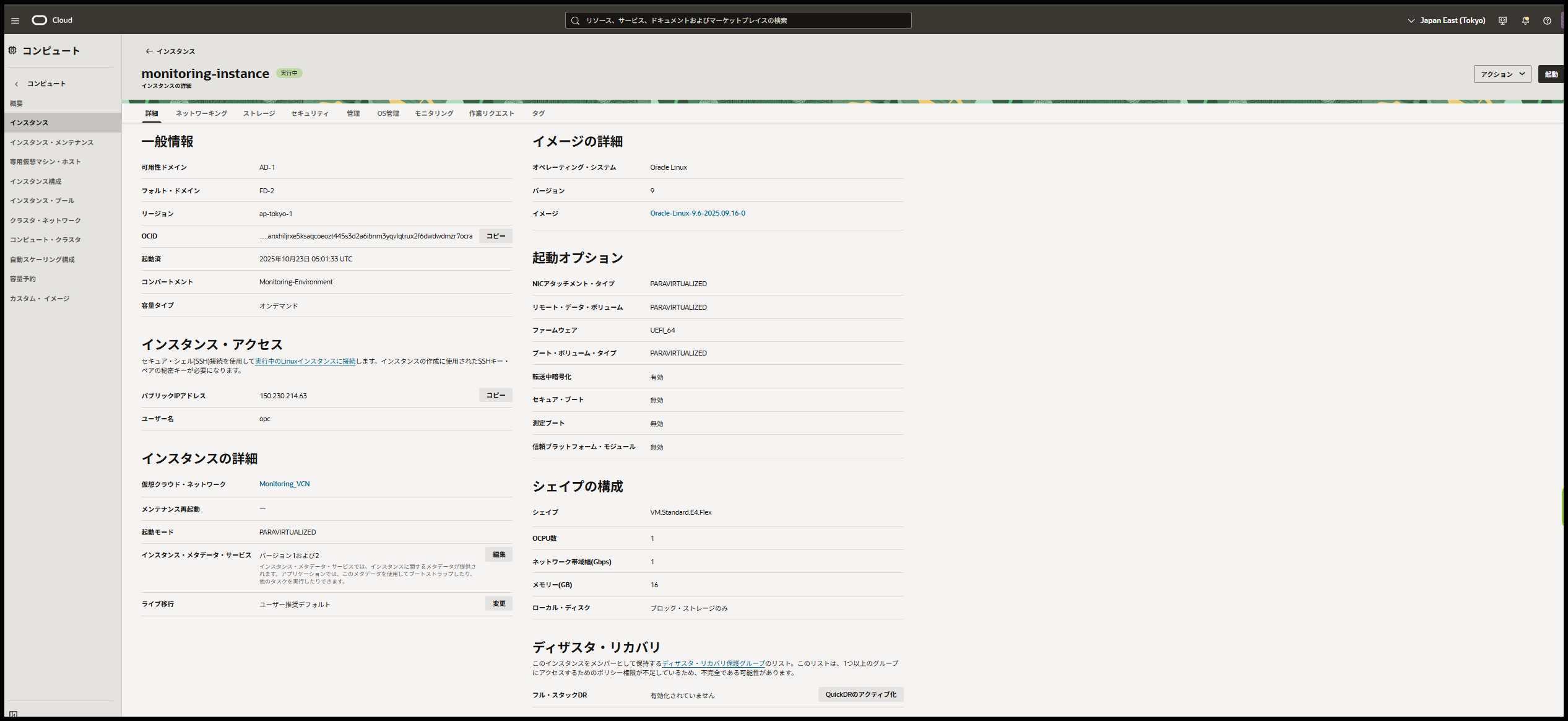
- イメージ: Oracle Linux 9
- シェイプ: VM.Standard.E4.Flex(1 OCPU、16GB RAM)
- ネットワーク: パブリックサブネット
- SSHキー: 新規作成または既存キーを使用
- Oracle Cloudエージェント: 管理エージェントのチェック
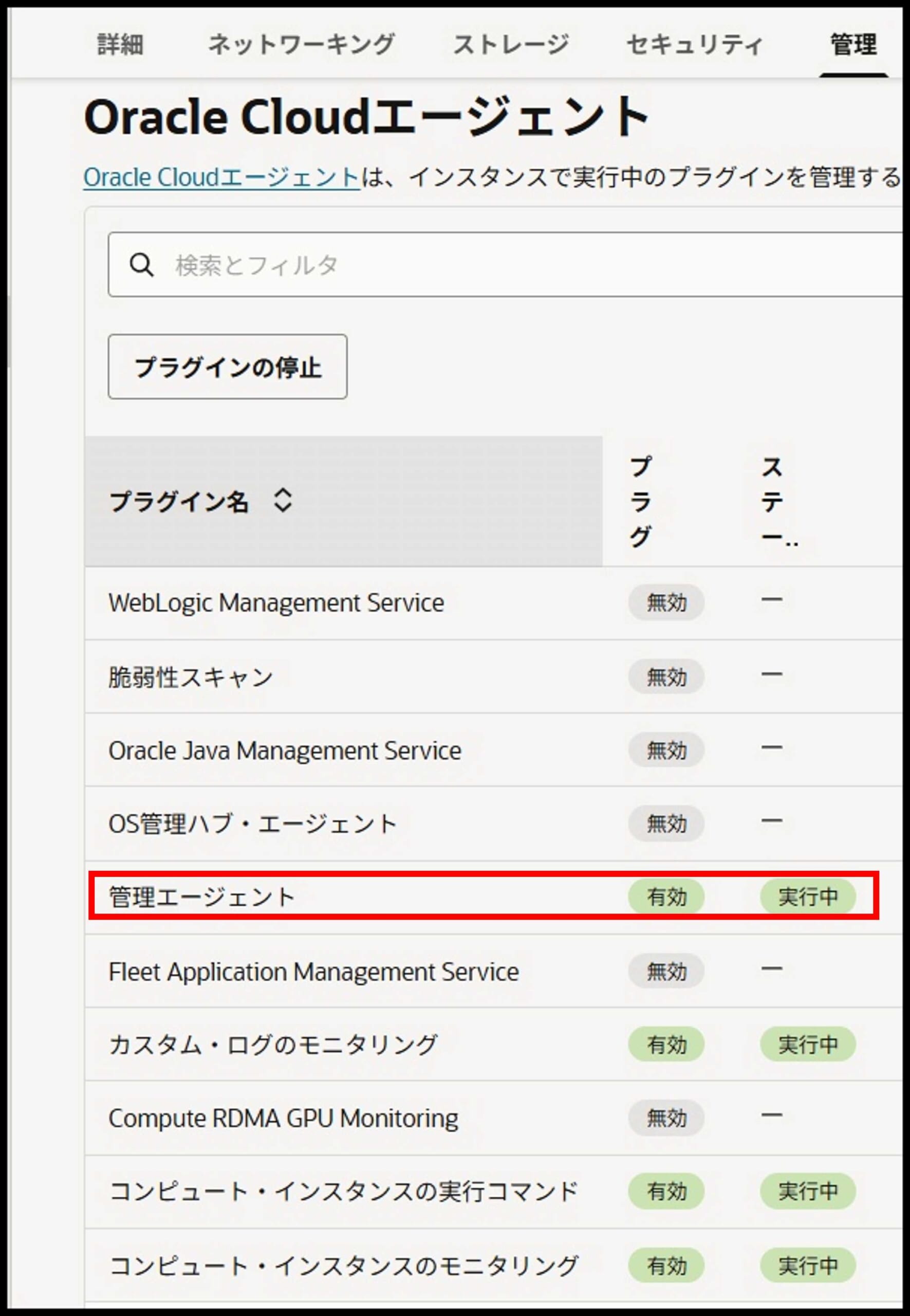
Oracle Cloud Agentの確認
インスタンス作成後、Oracle Cloud Agentのプラグインを確認します。
OCIコンソール → インスタンス詳細 →「管理」タブ → Oracle Cloudエージェント
Node Exporterのインストール
まず、メトリクスを公開するNode Exporterをインストールします。この手順は両方の方式で共通です。
SSHでインスタンスにログインし、Node Exporterをインストールします。
# インスタンスにSSH接続
ssh -i <秘密鍵のパス> opc@<パブリックIP>
# Node Exporterのダウンロード
wget https://github.com/prometheus/node_exporter/releases/download/v1.9.1/node_exporter-1.9.1.linux-amd64.tar.gz
# 解凍
tar xvfz node_exporter-1.8.2.linux-amd64.tar.gz
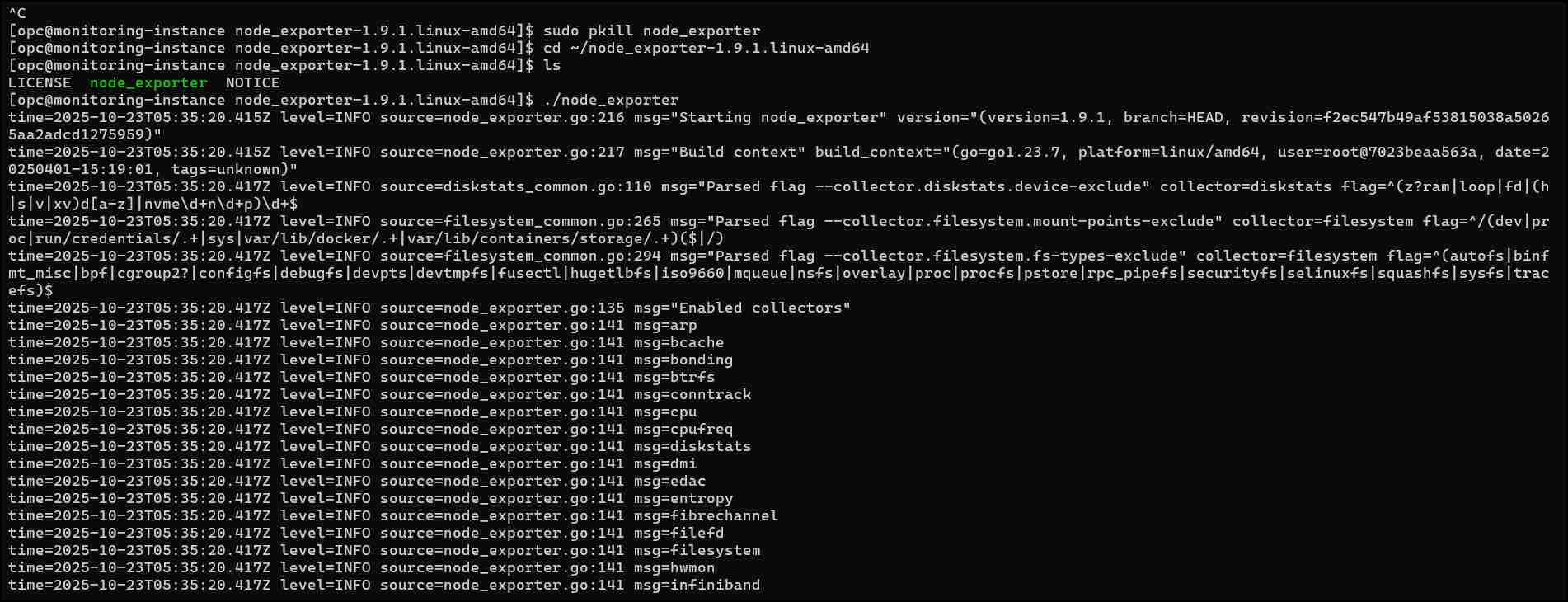
# 動作確認
./node_exporter
→ListeningしていたらOKです。


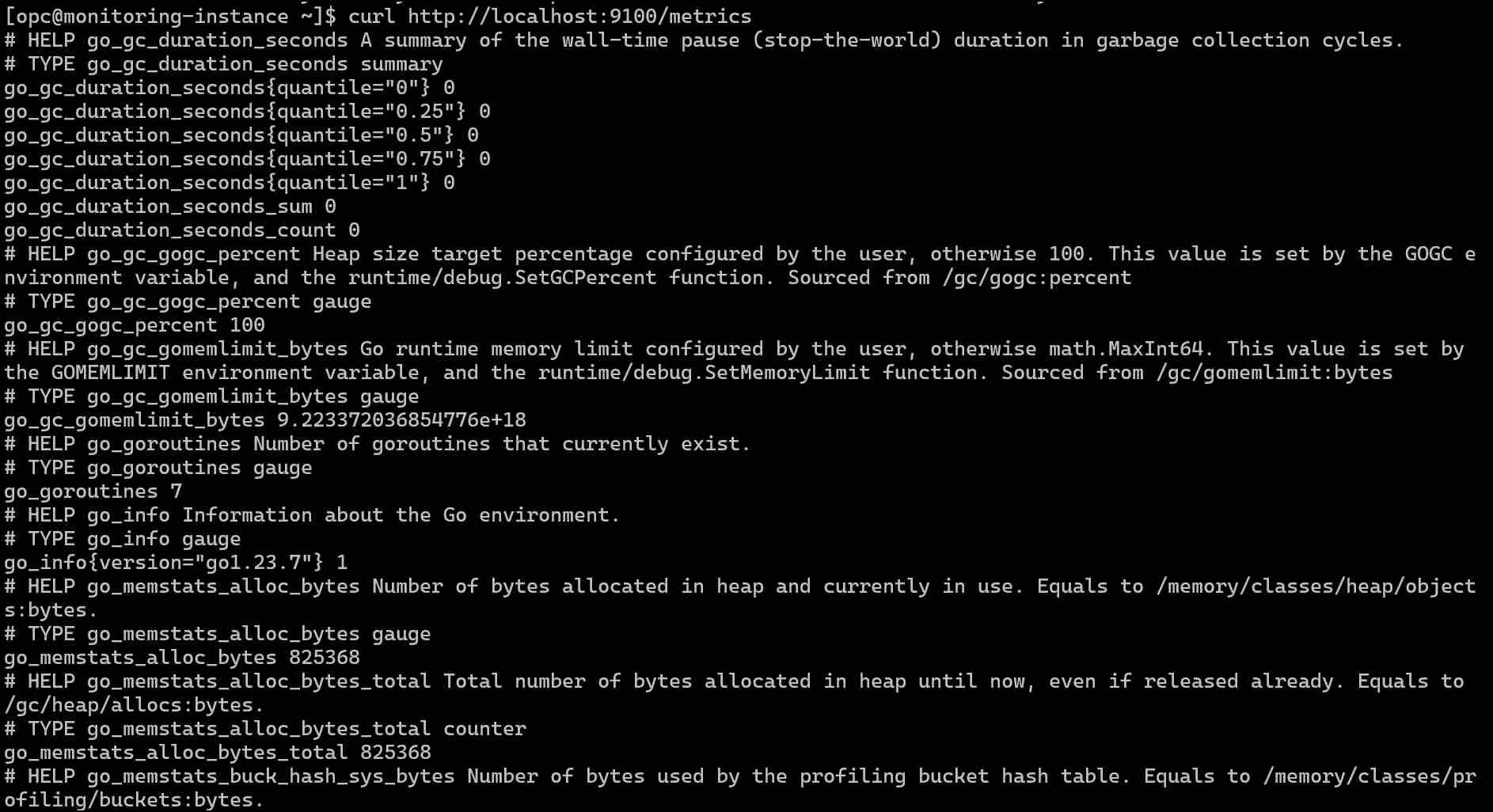
メトリクスの確認
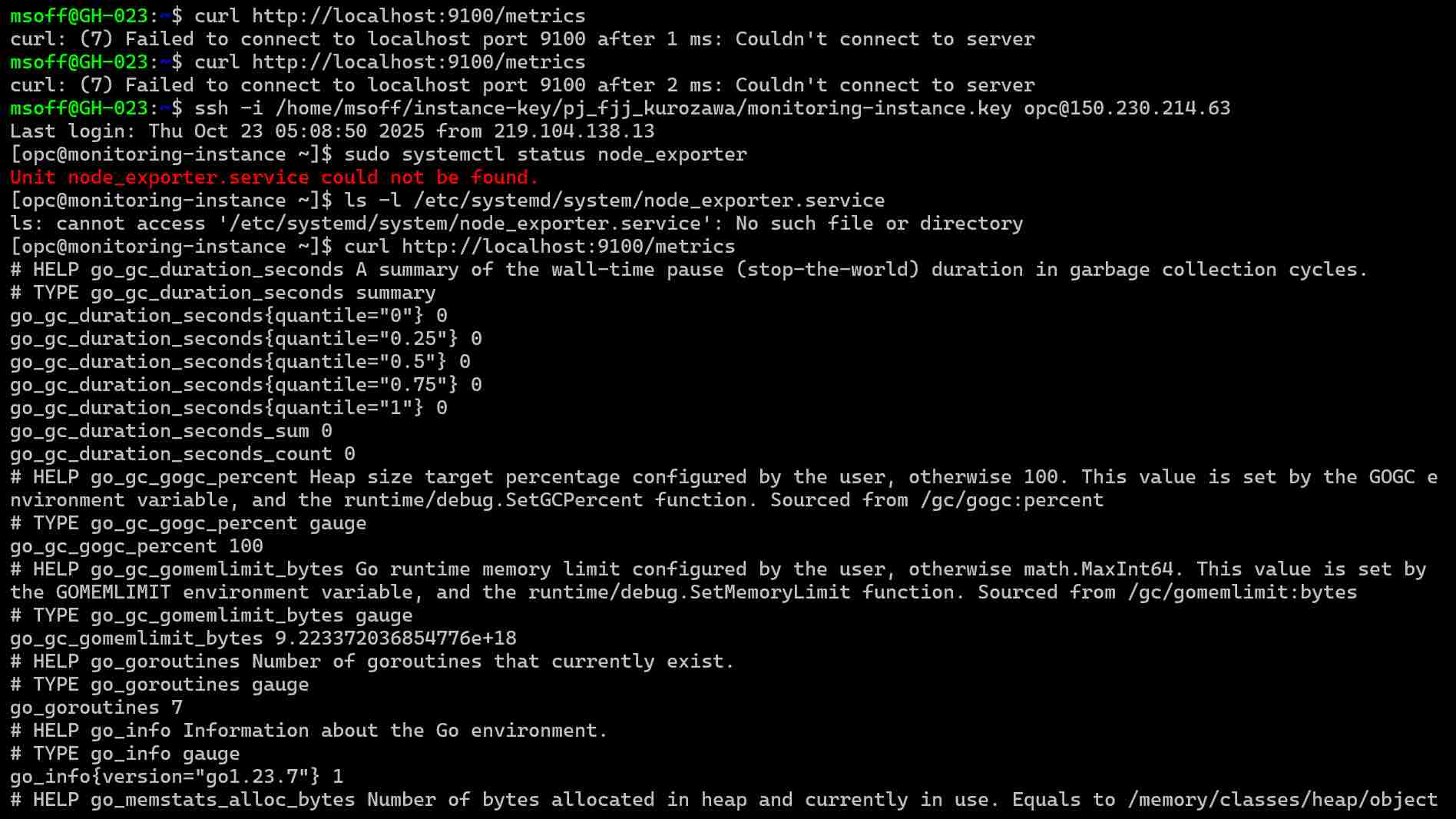
# メトリクスが取得できるか確認
curl http://localhost:9100/metrics
メトリクスが表示されればOKです。
💡 注意: Couldn't connect to server エラーが出る場合
この場合、Node Exporterがポート9100で待機していない場合があります。
一度、プロセスを終了させ、node_exporterファイルが存在するか確認してください。
確認後、再度Node Exporterを起動すると成功します。
【第1部】管理エージェント方式の構築
まずは、管理エージェント方式でメトリクス収集を構築します。この方法では、設定ファイルを手動で作成する必要があります。
Node Exporterのサービス化
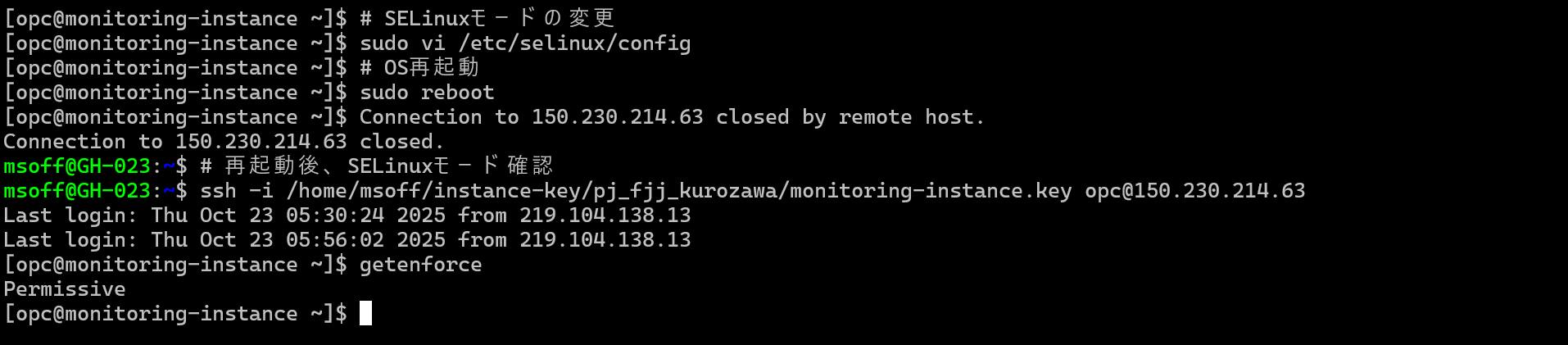
# SELinuxモードの変更
sudo vi /etc/selinux/config
# 以下のように変更(`enforcing` → `permissive`)
SELINUX=permissive
# OSを再起動
sudo reboot
# 再接続後、モードを確認
getenforce
💡 注意: 再起動後、SSH接続が切断されます。約1-2分待ってから再接続してください。
Permissive と表示されたらOKです。
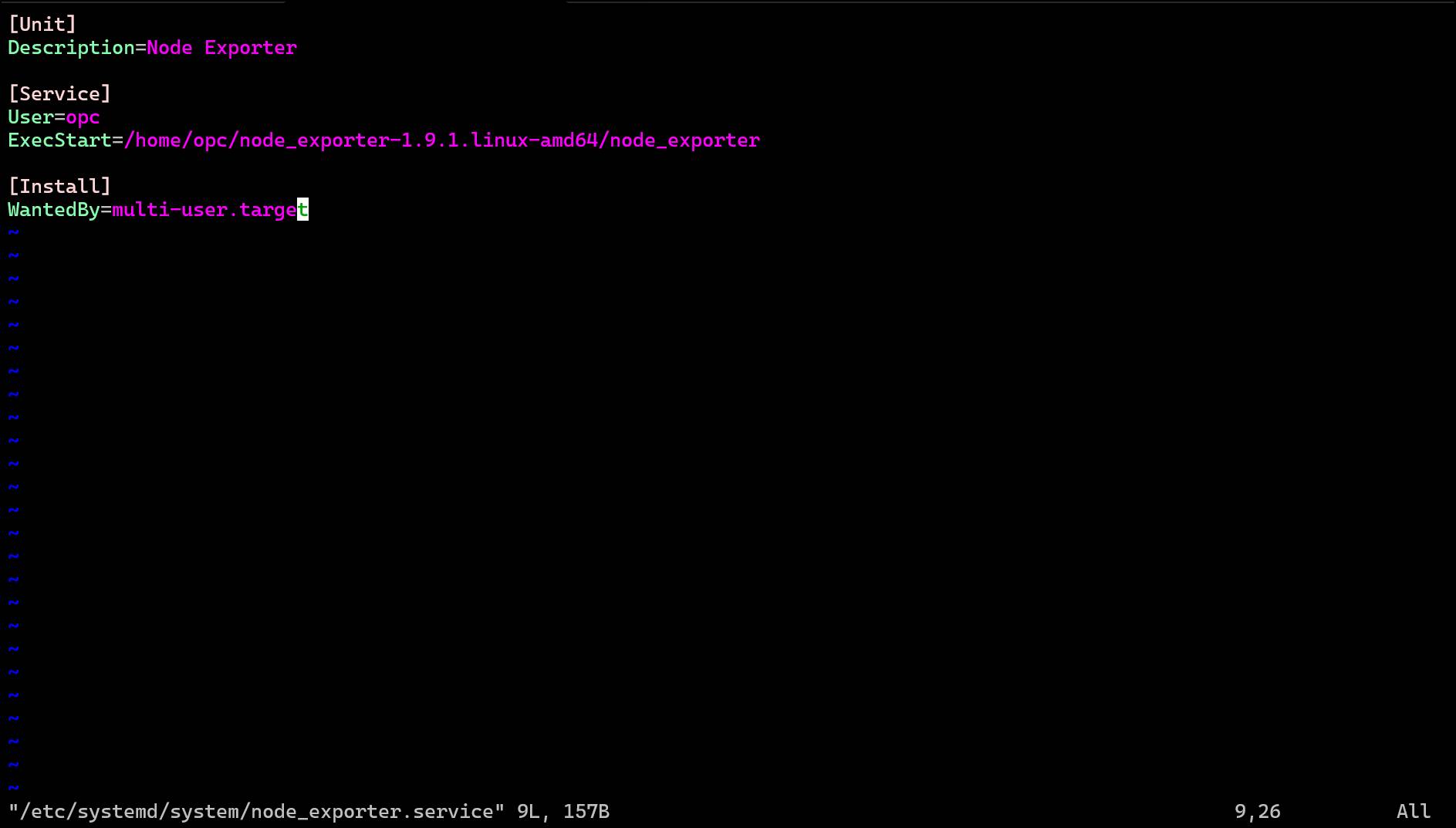
Systemdサービスファイルの作成
# Systemdサービスファイルの作成
sudo vi /etc/systemd/system/node_exporter.service
# 以下の内容を記述
[Unit]
Description=Node Exporter
[Service]
User=opc
ExecStart=/home/opc/node_exporter-1.9.1.linux-amd64/node_exporter
[Install]
WantedBy=multi-user.target
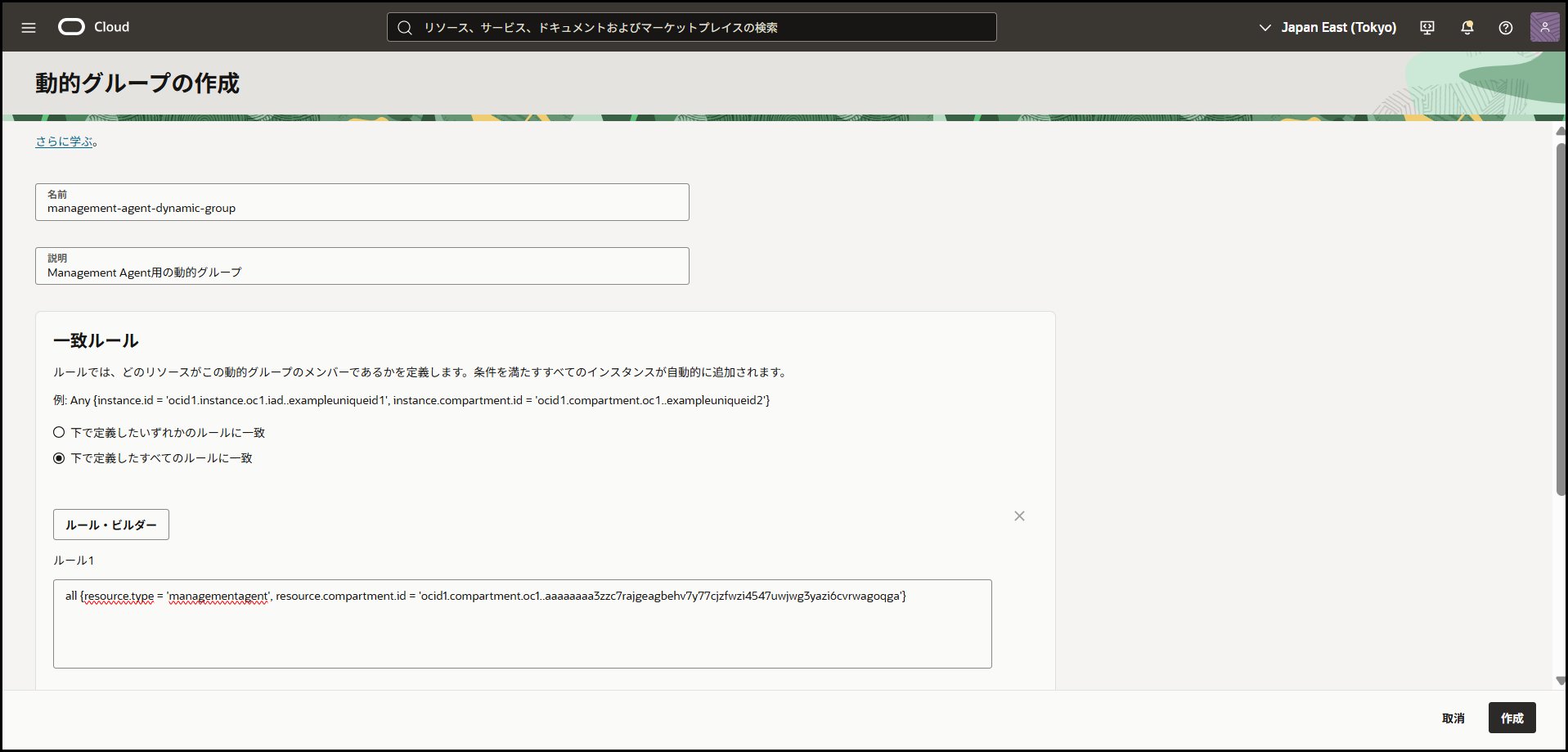
動的グループの作成
管理エージェント用の動的グループを作成します。
OCIコンソール → 「アイデンティティとセキュリティ」→「動的グループ」→「動的グループの作成」
設定値
- 名前:
management-agent-dynamic-group - 説明:
管理エージェント用動的グループ - ルール:
all {resource.type = 'managementagent', resource.compartment.id ='コンパートメントidʼ}
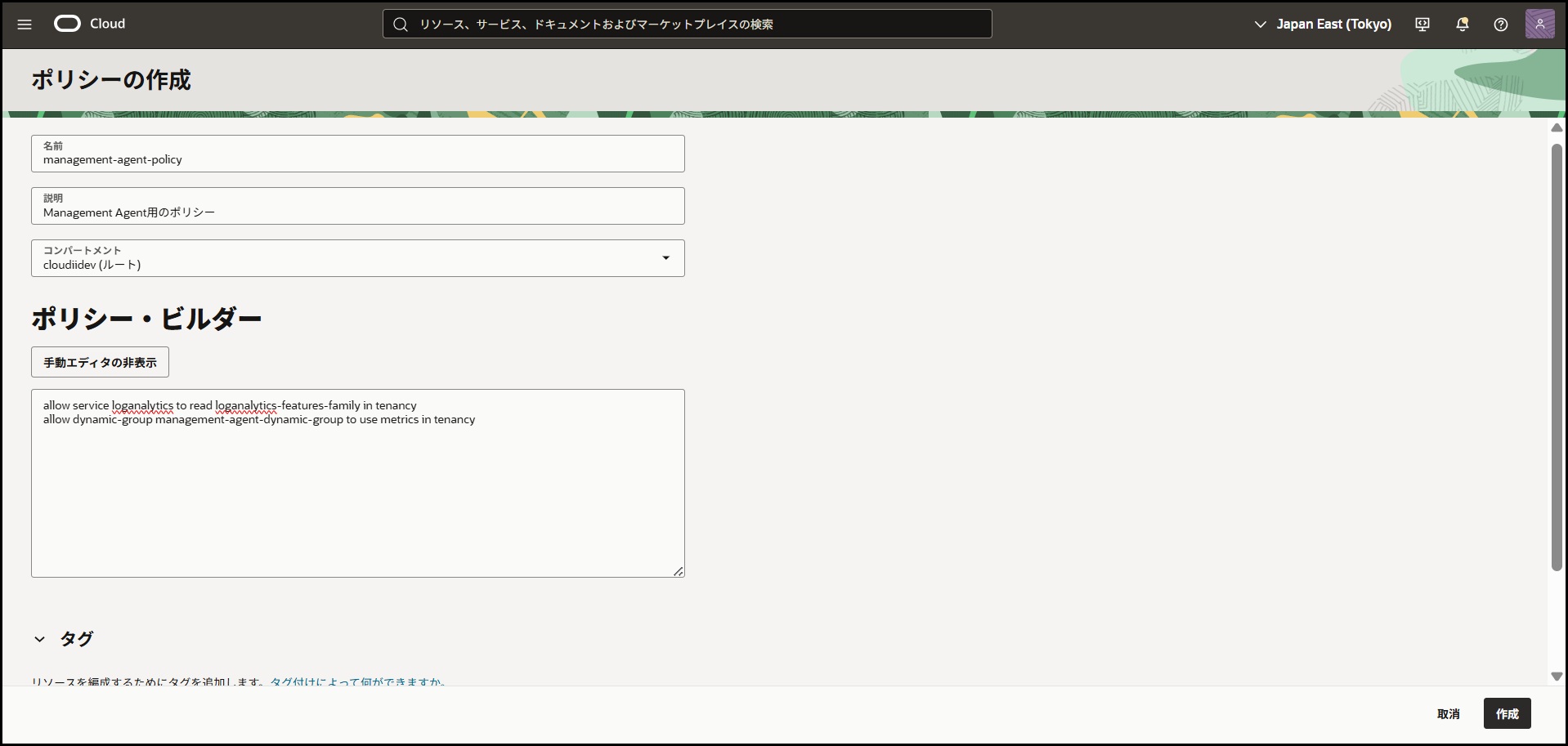
ポリシーの作成
管理エージェントがOCIモニタリングにメトリクスを送信できるようにポリシーを作成します。
OCIコンソール → 「アイデンティティとセキュリティ」→「ポリシー」→「ポリシーの作成」
設定値
- 名前:
management-agent-policy - 説明:
管理エージェント用ポリシー
ポリシー・ステートメント
allow service loganalytics to read loganalytics-features-family in tenancy
allow dynamic-group management-agent-dynamic-group to use metrics in tenancy
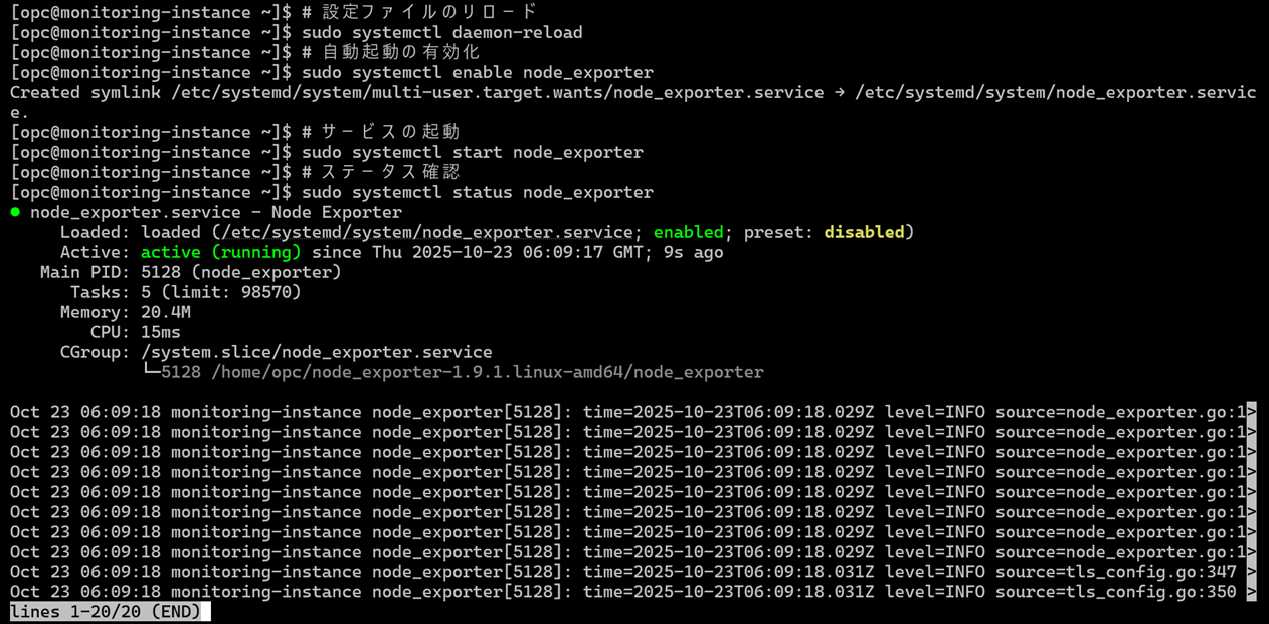
サービスの有効化と起動
先ほど作成した設定ファイルを再起動、有効化、サービスの起動とステータスの確認まで行っていきます。
# 設定ファイルのリロード
sudo systemctl daemon-reload
# 自動起動の有効化
sudo systemctl enable node_exporter
# サービスの起動
sudo systemctl start node_exporter
# ステータス確認
sudo systemctl status node_exporter
⚠️ ポイント: ステータスが Active (running)と表示されることを確認してください。
管理エージェントの設定
ここで管理エージェントの構成ファイルの配置を行います。OCIと管理エージェントが繋がる重要な設定になります。
ファイルの配置
# 構成ファイルの配置
sudo vi /var/lib/oracle-cloud-agent/plugins/oci-managementagent/polaris/agent_inst/discovery/PrometheusEmitter/monitoring.properties
# 設定内容
url=http://'プライベートIPアドレス':9100/metrics
namespace='任意の文字列'
compartmentId='コンパートメントid'
nodeName=monitoring-instance
metricDimensions=nodeName
# 収集するメトリックの制限
allowMetrics=収集するメトリック

以下が詳しい説明になります。
| 項目 | 説明 | 例 |
|---|---|---|
| url | Node ExporterのエンドポイントURL | http://10.0.0.237:9100/metrics |
| namespace | メトリックの名前空間 | demo_prometheus |
| compartmentId | 対象コンパートメントのOCID | ocid... |
| nodeName | インスタンスの識別名 | monitoring-instance |
| allowMetrics | 収集を許可するメトリック | node_cpu_seconds_total,node_memory... |
⚠️ ポイント: この.propertiesファイルは手動で作成する必要があります。インスタンスが増えるたびに、同じ作業を繰り返す必要があります。
メトリックの確認
OCIコンソールからメトリックを収集出来ているか確認します。
OCIコンソール → 「監視および管理」→「モニタリング」→「メトリック・エクスプローラ」
# 以下を選択して確認
- コンパートメント: インスタンスを作成したコンパートメント
- メトリック・ネームスペース: `demo_prometheus`(設定した値)を選択
- メトリック名: 設定したメトリックが選択肢に表示される
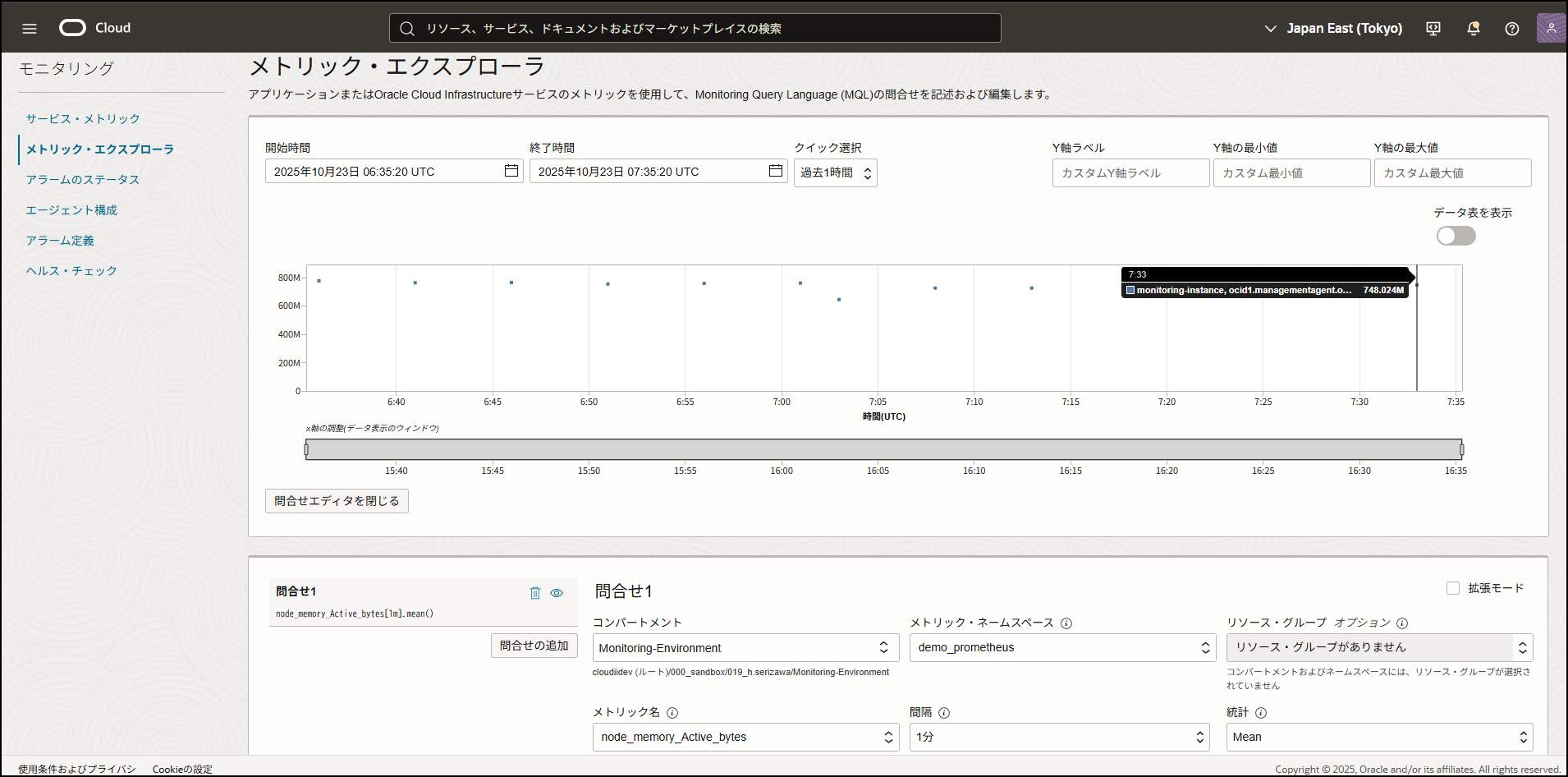
メトリクスが表示されれば、管理エージェント方式での構築は完了です。
振り返り
管理エージェント方式では、以下の作業が必要でした。
- ✗ SSHでログイン
- ✗ 設定ファイルを手動作成
- ✗ ディレクトリやパスを正確に指定
- ✗ エージェントの再起動
この作業を、インスタンスごとに繰り返す必要があります。
💭 悩み: もっと簡単な方法はないのか?→ あります!次の第2部で紹介します。
【第2部】Loggingエージェント方式への移行
ここからは、Loggingエージェント方式に移行します。
管理エージェントの無効化
第一部での管理エージェントを無効化しておきます。
OCIコンソール → インスタンス詳細 →「管理」タブ → Oracle Cloudエージェント
Unified Monitoring Agentの確認
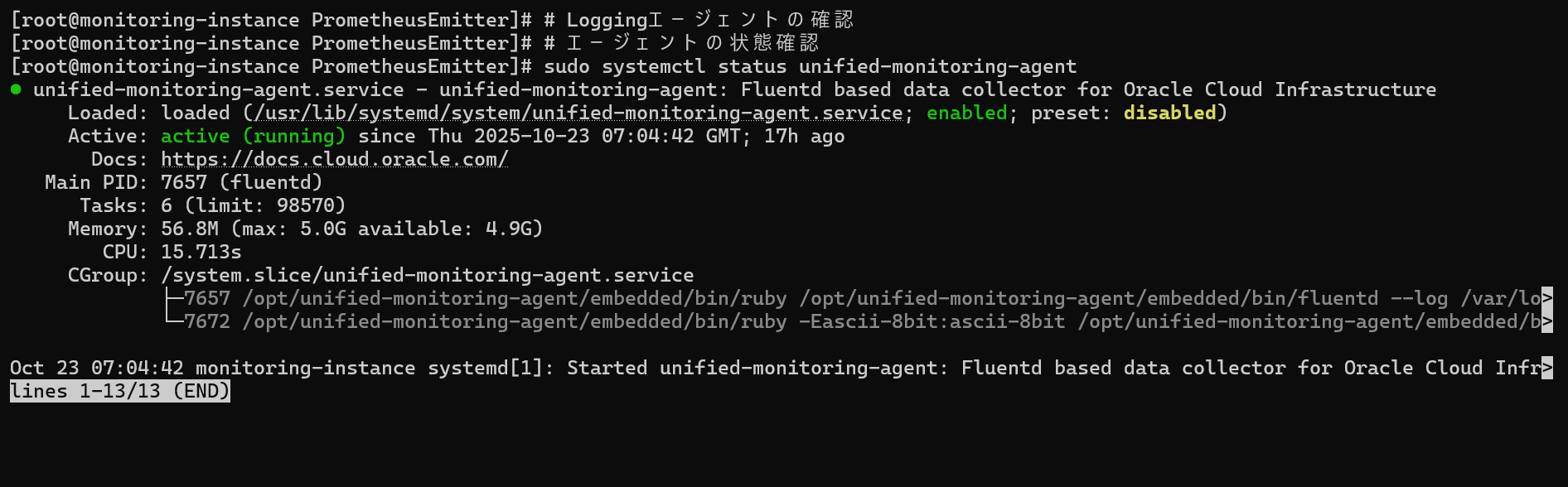
Loggingエージェントは Unified-Monitoring-Agent という名前で動作しています。
# エージェントがインストールされているか確認
sudo systemctl status unified-monitoring-agent
⚠️ ポイント: 以下のように「active (running)」と表示されればOKです。
動的グループの作成
Loggingエージェント用の動的グループを作成します。
OCIコンソール → 「アイデンティティとセキュリティ」→「動的グループ」→「動的グループの作成」
設定値
- 名前:
logging-agent-dynamic-group - 説明:
Loggingエージェント用動的グループ - ルール:
all {instance.compartment.id ='コンパートメントidʼ]
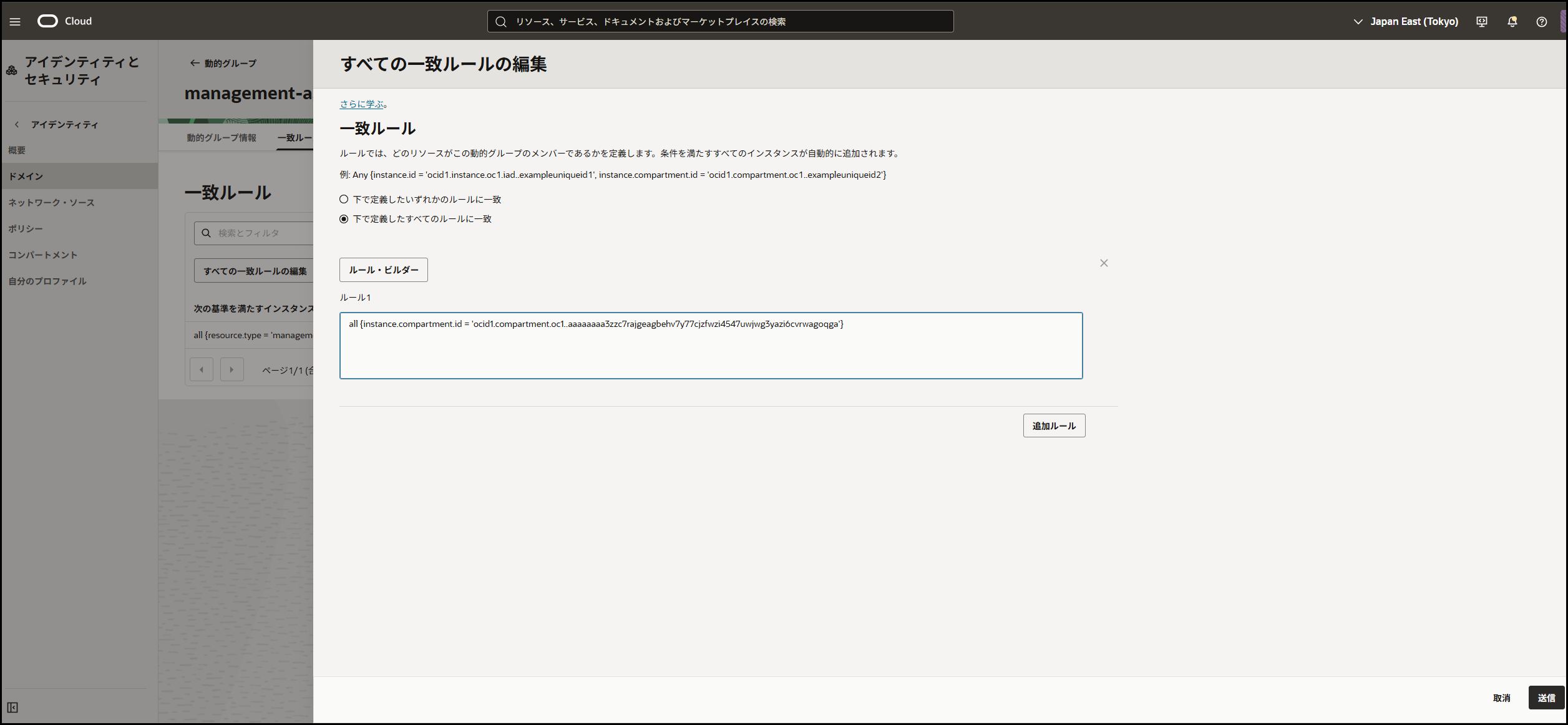
💡 管理エージェントとの違い: resource.type = managementagent ではなく、instance.compartment.id を使用します。
ポリシーの作成
Loggingエージェント用のポリシーを作成します。
OCIコンソール → 「アイデンティティとセキュリティ」→「ポリシー」→「ポリシーの作成」
設定値
- 名前:
logging-agent-policy - 説明:
Loggingエージェント用ポリシー
ポリシー・ステートメント
Allow dynamic-group logging-agent-dynamic-group to use metrics in compartment id コンパートメントid
Allow dynamic-group logging-agent-dynamic-group to use log-content in compartment id コンパートメントid
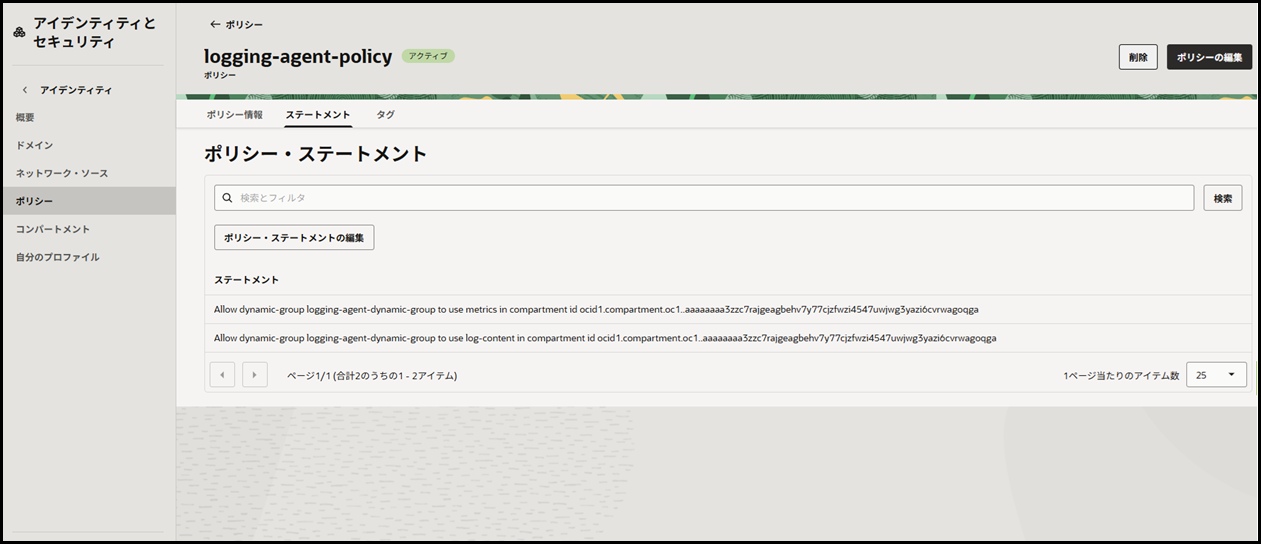
💡 ポリシーの説明
use metrics: OCIモニタリングにメトリクスを送信する権限
manage unified-configuration: エージェント構成を管理する権限
エージェント構成の作成
OCIコンソールで設定を入力するだけで、設定ファイルが自動生成されます。
OCIコンソール → 「監視および管理」→「モニタリング」 → 「エージェント構成」→「エージェント構成の作成」
⚠️ 注意
- ✅ 「モニタリング → エージェント構成」から作成してください
- ❌ 「ロギング → エージェント構成」からは、メトリクス収集用の構成は作成できません
- 📊 作成後のエージェント構成は「ロギング → エージェント構成」でも確認できます(モニタリングタブ)
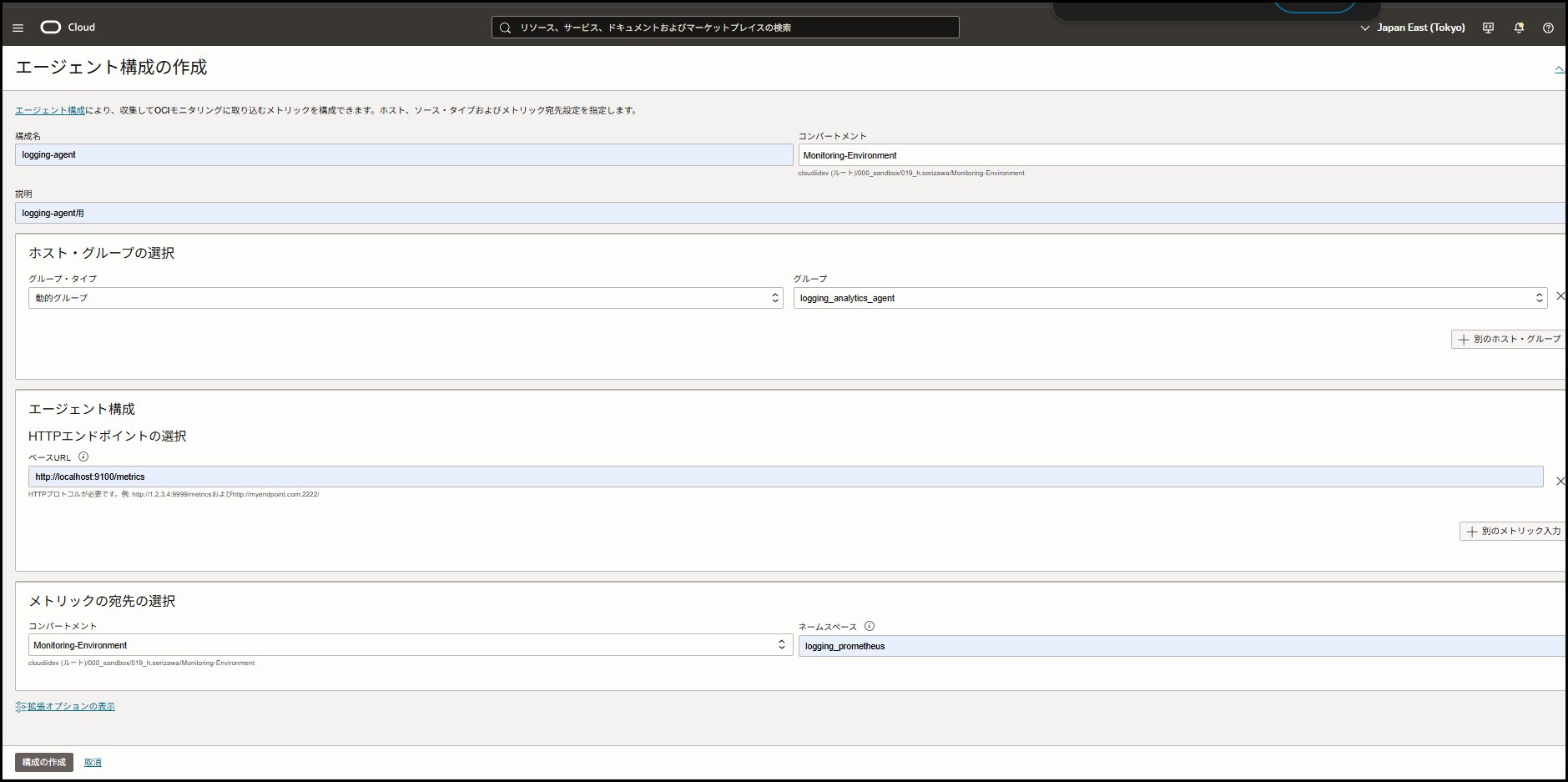
# 構成名構成名:logging-agent説明:logging-agent用コンパートメント: インスタンスと同じコンパートメント# ホスト・グループの選択「ホスト・グループ」タブをクリック 「動的グループの選択」を選択 先ほど作成したlogging-agent-dynamic-groupを選択# エージェント構成HTTPエンドポイントの選択 ベースURL:http://localhost:9100/metrics # メトリックの宛先の選択コンパートメント: インスタンスと同じコンパートメント ネームスペース:logging_prometheus
💡 重要な違い: 管理エージェントではdemo_prometheusでしたが、今回はlogging_prometheusを使用します。
作成後、ステータスが「ACTIVE」になることを確認してください。
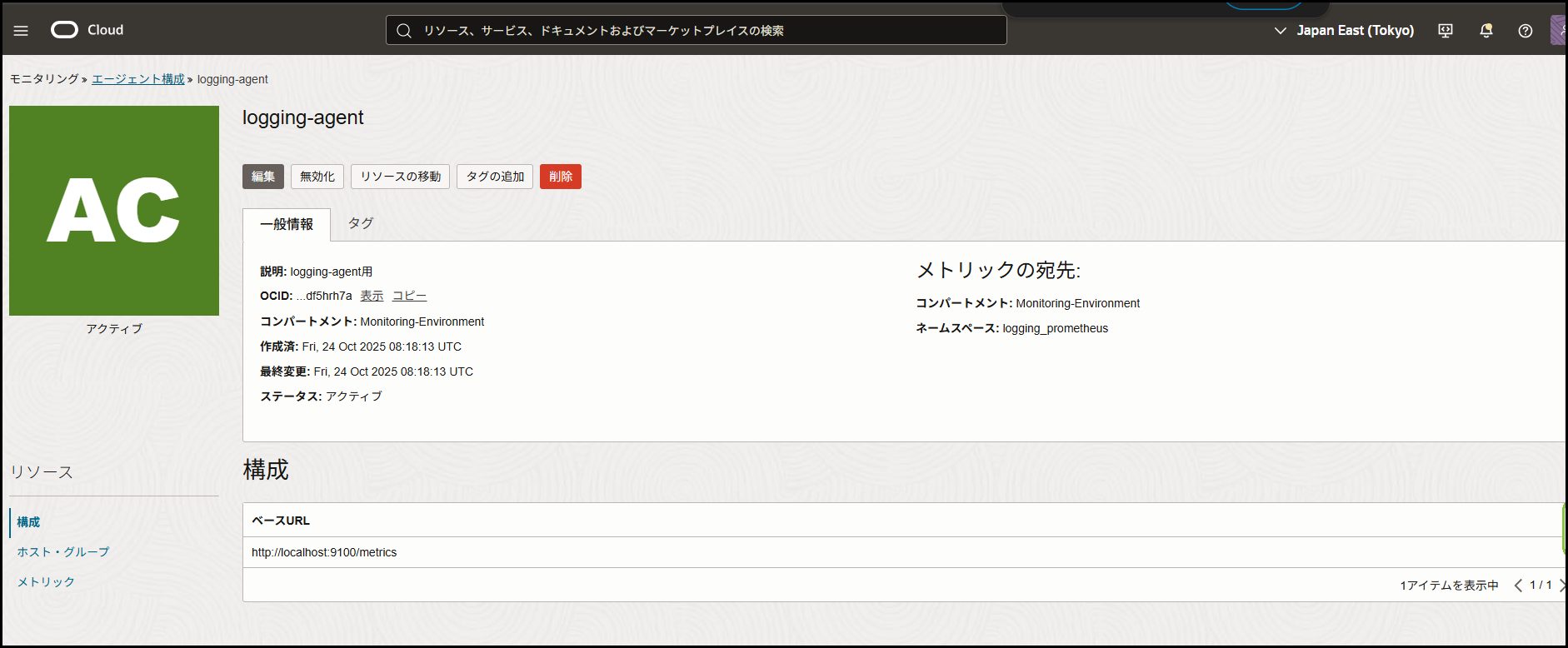
✨ ここがすごい!: これだけです!SSHログインも、設定ファイルの手動作成も不要です。
動作確認
インスタンスにSSH接続し、設定ファイルが自動生成されているか確認します。
# 設定ファイルの確認
sudo ls -la /etc/unified-monitoring-agent/conf.d/fluentd_config/
# 設定ファイルの内容を表示
sudo cat /etc/unified-monitoring-agent/conf.d/fluentd_config/fluentd.conf
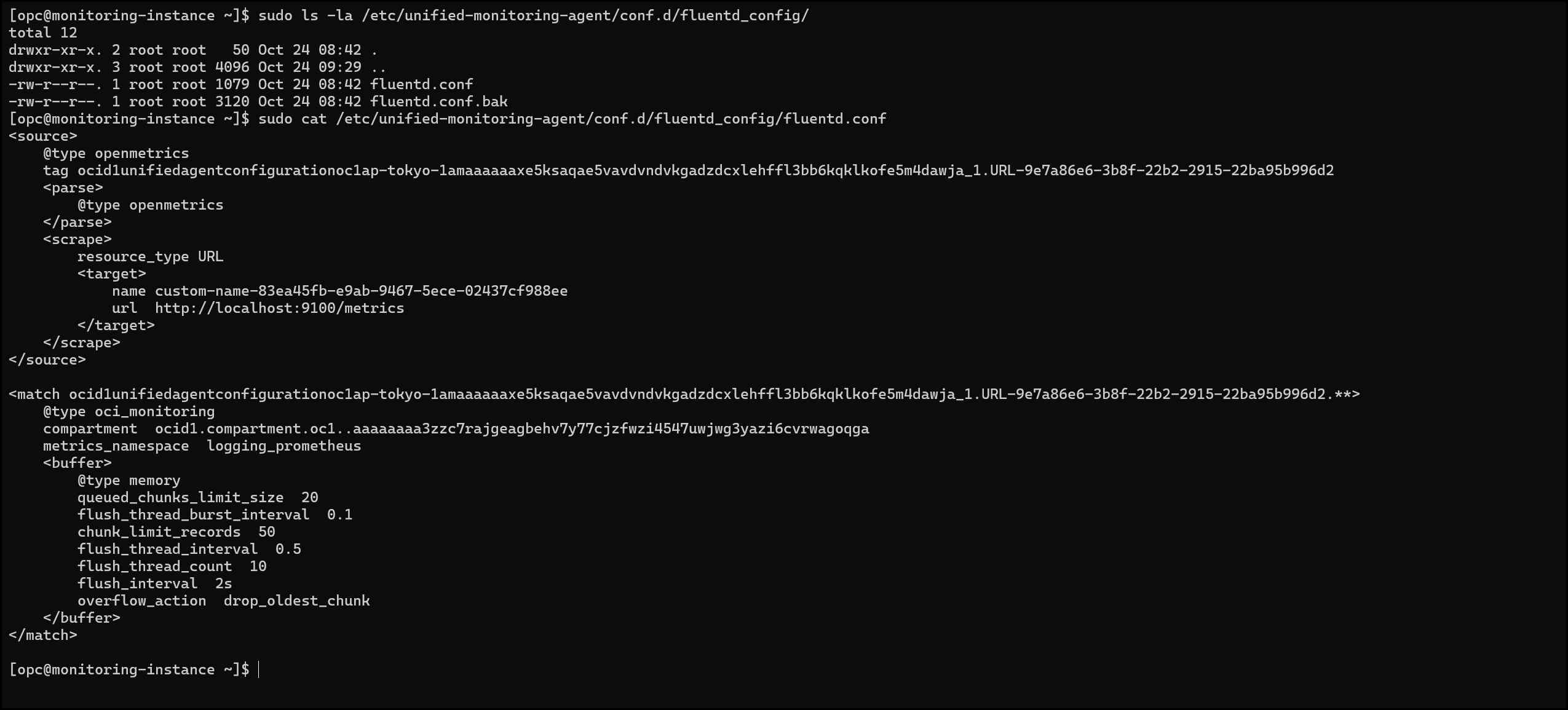
💡ポイント: OCIコンソールで入力した内容が、そのまま設定ファイルになっています!
エージェントのログを確認
# エージェントがメトリクスを収集しているか確認
sudo tail -50 /var/log/unified-monitoring-agent/unified-monitoring-agent.log | grep "Parsed.*metrics"
以下のようなログが表示されればOKです
2025-10-27 04:27:32 +0000 [info]: #0 Parsed 674 metrics.
2025-10-27 04:27:42 +0000 [info]: #0 Parsed 674 metrics.

OCIモニタリングで確認
- OCIコンソール → 「モニタリング」 → 「メトリクス・エクスプローラ」
- メトリクス・ネームスペース:
logging_prometheusを選択
メトリクスが表示されていれば、移行完了です!🎉

振り返り
Loggingエージェント方式ではOCIコンソールでエージェント構成を作成だけで完了しました。
設定ファイルの手動作成、CLI構築作業、エージェントの再起動が不要です。
📊 2つの方式の徹底比較
作業フローの比較
管理エージェント方式
1. 管理エージェントのインストール(手動) 2. 動的グループの作成 3. ポリシーの作成 4. SSHでログイン 5. 設定ファイルを手動作成 6. エージェントの再起動 7. 動作確認
Loggingエージェント方式
1. Oracle Cloud Agentプラグイン有効化(クリック1回) 2. 動的グループの作成 3. ポリシーの作成 4. エージェント構成の作成(OCIコンソール) 5. 動作確認
詳細比較表
| 項目 | 管理エージェント | Loggingエージェント |
|---|---|---|
| エージェントのインストール | 自動(プラグイン有効化) | 自動(プラグイン有効化) |
| 設定ファイル | .properties(手動作成) | fluentd.conf(自動生成) |
| 設定ファイルの場所 | /var/lib/oracle-cloud-agent/... | /etc/unified-monitoring-agent/... |
| 設定方法 | SSH + ファイル編集 | OCIコンソール |
| 複数インスタンスへの設定 | インスタンスごとに手動設定 | OCIコンソールで一括設定 |
| メトリクスの指定方法 | propertiesファイルで指定 | Node Exporter側で指定(全メトリクス公開) |
| 必要な権限 | use metrics | use metrics + manage unified-configuration |
| スケーラビリティ | 低い(N個 = N回作業) | 高い(N個 = 1回作業) |
| 設定ミスのリスク | 高い(手動入力) | 低い(GUI入力) |
メトリクス・ネームスペースの違い
| 方式 | ネームスペース |
|---|---|
| 管理エージェント | demo_prometheus(任意の名前) |
| Loggingエージェント | logging_prometheus(任意の名前) |
設定ファイルの比較
管理エージェント方式(.properties)
# シンプルだが、手動作成が必要
namespace=demo_prometheus
allowMetrics=.*
metricsURL=http://localhost:9100/metrics
Loggingエージェント方式(fluentd.conf)
# 複雑に見えるが、自動生成される
@type oci_monitoring
compartment ocid1.compartment.oc1..
metrics_namespace logging_prometheus
<buffer>
@type memory
queued_chunks_limit_size 20
flush_thread_burst_interval 0.1
chunk_limit_records 50
flush_thread_interval 0.5
flush_thread_count 10
flush_interval 2s
overflow_action drop_oldest_chunk
</buffer>
</match>
✅ まとめ:どちらを選ぶべきか
管理エージェント方式を選ぶべきケース
- 既存のインフラで管理エージェントを使用している
- 送信するメトリクスを細かく制御したい
- インスタンスごとに個別に設定を行う場合
Loggingエージェント方式を選ぶべきケース
- ✅ 新規でメトリクス収集を始める
- ✅ 複数インスタンスの設定をまとめて行う場合
- ✅ 動的にインスタンスが増減する
- ✅ 設定変更を頻繁に行う
- ✅ 手作業を減らしたい(最重要!)
最後に
この記事では、管理エージェント方式からLoggingエージェント方式への移行を、実際に手を動かしながら紹介させていただきました。
結論: 設定ファイルの手動作成という面倒な作業が、OCIコンソールでの設定だけで完結するようになりました。これにより、大幅な作業時間の削減とスケーラビリティの向上が期待できます。
この記事を通じ、皆様の問題解決の一助となれば幸いです。
最後まで読んで頂き、ありがとうございました。
参考リンク